我正在使用JMH来测试DOM解析器的性能。我得到了非常奇怪的结果,因为第一次迭代实际上比后面的迭代运行得更快。
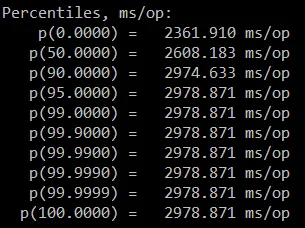
 有人能解释一下这是为什么吗?还有,百分位数和所有数字的含义是什么,为什么在第三次迭代后开始变得稳定?一个迭代是否意味着整个基准测试方法的一次迭代?以下是我正在运行的方法:
有人能解释一下这是为什么吗?还有,百分位数和所有数字的含义是什么,为什么在第三次迭代后开始变得稳定?一个迭代是否意味着整个基准测试方法的一次迭代?以下是我正在运行的方法:
有人能解释一下这是为什么吗?还有,百分位数和所有数字的含义是什么,为什么在第三次迭代后开始变得稳定?一个迭代是否意味着整个基准测试方法的一次迭代?以下是我正在运行的方法:@Benchmark
@BenchmarkMode(Mode.SingleShotTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Warmup(iterations = 13, time = 1, timeUnit = TimeUnit.MILLISECONDS)
public void testMethod_no_attr() {
try {
File fXmlFile = new File("500000-6.xml");
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse(fXmlFile);
} catch (Exception e) {
e.printStackTrace();
}
}