 我正在从一个包含时间戳的txt文件中读取数据。我需要从txt文件中读取数据并将结果写入另一个txt文件。因此,我需要对数据进行排序。
我正在从一个包含时间戳的txt文件中读取数据。我需要从txt文件中读取数据并将结果写入另一个txt文件。因此,我需要对数据进行排序。
例如,我需要计算2020-08-28T11:46:24.8419656Z和2020-08-28T11:48:11.8418281Z之间XXXXXX的时间差,即总时间差。要计算“执行”时间,我需要减去2020-08-28T11:48:11.8418281Z和2020-08-28T11:46:39.9417366Z之间的时间。这些只是计算时间差的示例。如果出现错误,则需要在“测试状态”中打印为1。如果YYYYYY中存在错误,则只需将时间状态分配为0。在输出中,我给出了值以将它们显示为示例。
我该如何计算时间差,因为时间戳中间有T?另一个挑战是我需要根据列中的标签计算两行之间的差异。为了找到时间戳的名称(例如XXXXXXXX),我需要检查“#########”,然后才能进行排序,否则我不知道txt文件中出现的名称是哪个。from datetime import datetime
def time_diff(start, end):
start_dt = datetime.strptime(start, '%H:%M:%S')
end_dt = datetime.strptime(end, '%H:%M:%S')
diff = (end_dt - start_dt)
return diff.seconds
scores = {}
with open('input.txt') as fin:
for line in fin.readlines():
values = line.split(',')
scores[values[0]] = time_diff(values[0],values[0])
with open('result.txt', 'w') as fout:
for key, value in sorted(scores.iteritems(), key=lambda (k,v): (v,k)):
fout.write('%s,%s\n' % (key, value))
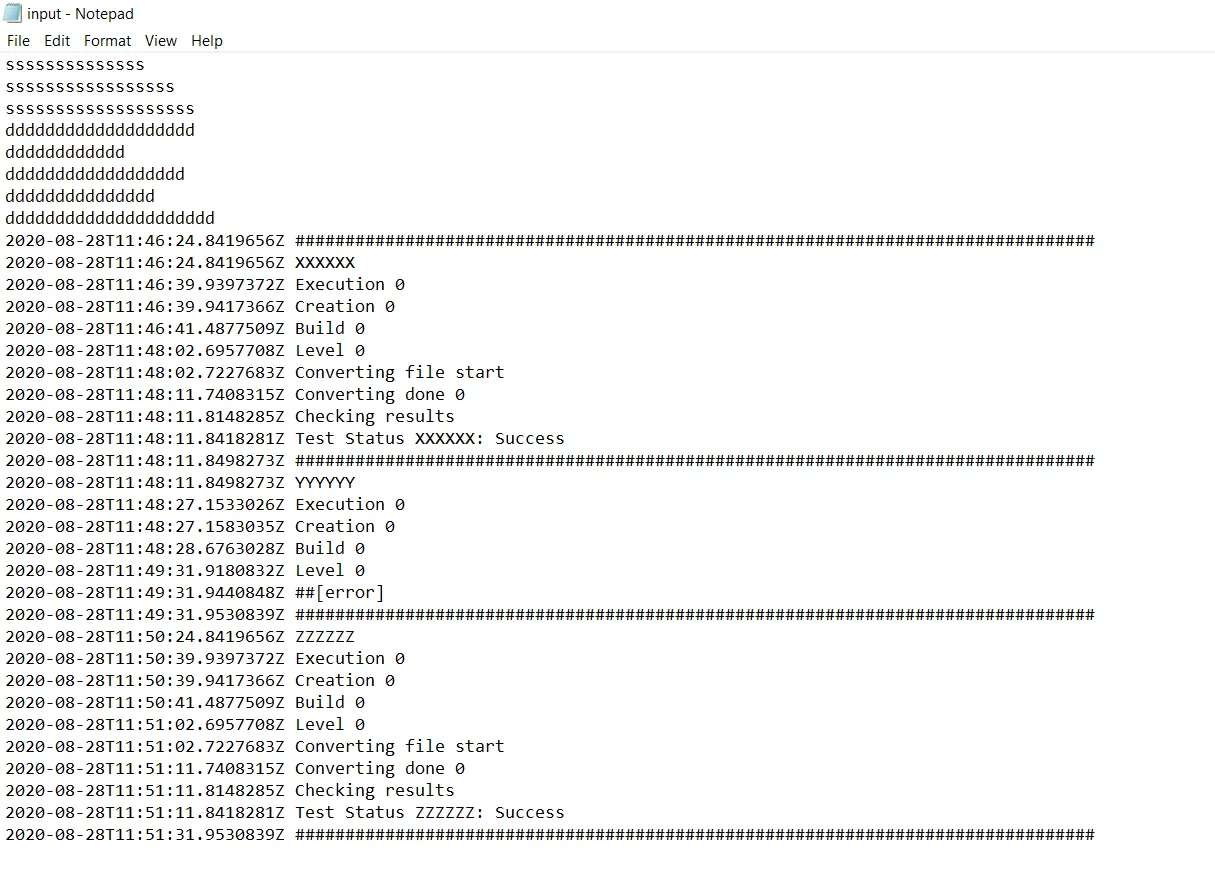
INPUT:
2020-08-28T11:46:24.8419656Z ################################################################################
2020-08-28T11:46:24.8419656Z XXXXXX
2020-08-28T11:46:39.9397372Z Execution 0
2020-08-28T11:46:39.9417366Z Creation 0
2020-08-28T11:46:41.4877509Z Build 0
2020-08-28T11:48:02.6957708Z Level 0
2020-08-28T11:48:02.7227683Z Converting file start
2020-08-28T11:48:11.7408315Z Converting done 0
2020-08-28T11:48:11.8148285Z Checking results
2020-08-28T11:48:11.8418281Z Test Status XXXXXX: Success
2020-08-28T11:48:11.8498273Z ################################################################################
2020-08-28T11:48:11.8498273Z YYYYYY
2020-08-28T11:48:27.1533026Z Execution 0
2020-08-28T11:48:27.1583035Z Creation 0
2020-08-28T11:48:28.6763028Z Build 0
2020-08-28T11:49:31.9180832Z Level 0
2020-08-28T11:49:31.9440848Z ##[error]
2020-08-28T11:49:31.9530839Z ################################################################################
2020-08-28T11:50:24.8419656Z ZZZZZZ
2020-08-28T11:50:39.9397372Z Execution 0
2020-08-28T11:50:39.9417366Z Creation 0
2020-08-28T11:50:41.4877509Z Build 0
2020-08-28T11:51:02.6957708Z Level 0
2020-08-28T11:51:02.7227683Z Converting file start
2020-08-28T11:51:11.7408315Z Converting done 0
2020-08-28T11:51:11.8148285Z Checking results
2020-08-28T11:51:11.8418281Z Test Status ZZZZZZ: Success
2020-08-28T11:51:31.9530839Z ################################################################################
OUTPUT:
Name Total Execution Creation Build Level Converting Checking results Test Status
XXXXXX 10 2 2 2 2 2 2 2 0
YYYYYY 10 2 2 2 2 0 0 0 1
ZZZZZZ 10 2 2 2 2 2 2 2 0
INPUT和input.txt是一样的吗?因为我在INPUT中没有看到任何逗号。请附上input.txt文件的图像。 - r0ot293dateutil.parser.isoparse转换为datetime对象。以下是如何进行操作的链接(https://discuss.python.org/t/parse-z-timezone-suffix-in-datetime/2220)。 - r0ot293