我遇到的问题是从图像中提取文本,我使用了Tesseract v3.02。我需要从一些涉及仪表读数的示例图像中提取文本,其中一些具有固体背景,而另一些具有LED显示。我已经对具有固体背景的数据集进行了训练,结果还算有效。
现在我面临的主要问题是无法识别Tesseract的LED / LCD背景下的文本图像,因此无法生成训练集。 是否有人可以指导我如何使用Tesseract和七段数码管(LCD / LED背景),或者是否有其他替代方案可供我使用。
图片链接如下: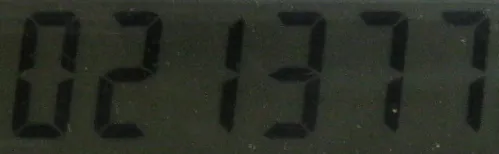
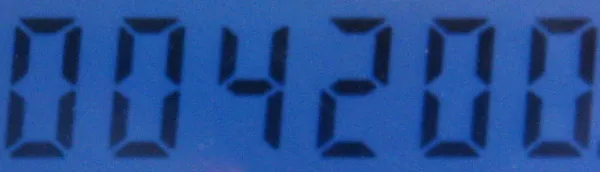
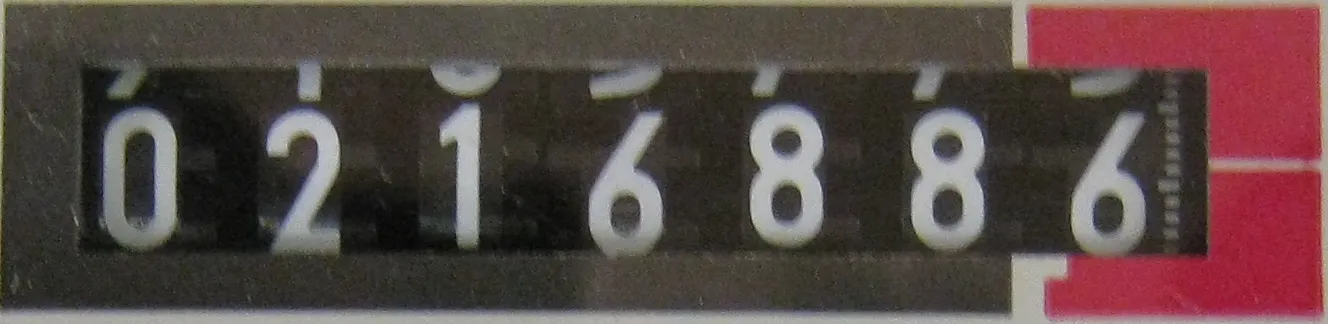


现在我面临的主要问题是无法识别Tesseract的LED / LCD背景下的文本图像,因此无法生成训练集。 是否有人可以指导我如何使用Tesseract和七段数码管(LCD / LED背景),或者是否有其他替代方案可供我使用。
图片链接如下: