在理想情况下,您需要索引出现在WHERE子句或JOIN条件中的列。在您的情况下,这将是Email和Password列。
因此,您可以在用户表和电子邮件和密码上使用非聚集索引。
因此,基本上这个索引:
CREATE NONCLUSTERED INDEX idx_User_Email_Password
ON dbo.User (Email, Password);
因此,如果您运行此查询:
SELECT UserID, UserName
FROM User
WHERE Email = 'something'
AND Password = 'something';
你最终会使用刚刚创建的索引(很可能是聚集索引),并通过它来查找。然而,你的查询选择了UserID和UserName,它们没有包含在你的索引中,结果会进行键值查找(它会在创建的索引中找到记录,并回到你的dbo.User表中查找SELECT语句匹配的值(UserID和UserName)。为了避免这种情况,你可以创建带有INCLUDED列的索引,以消除键值查找(你肯定要这样做)。
CREATE NONCLUSTERED INDEX idx_User_Email_Password
ON dbo.User (Email, Password)
INCLUDE (UserID, UserName);
使用这个索引,你将在执行计划中得到一个不错的非聚集索引查找。
此外,选择索引列的顺序很重要。假设你的表包含UserTypeID(数量不多)。那么如果你传递了一些特定的UserTypeID和一组UserIDs,SQL Server可能会选择以UserTypeID作为第一个索引列的索引。
所以进行一些测试:
CREATE TABLE #Users
(
UserId INT
, UserName VARCHAR(500)
, Email VARCHAR(500)
, Password VARCHAR(500)
);
CREATE CLUSTERED INDEX idx_Users_UserID
ON #Users (UserID);
INSERT INTO #Users (UserId, UserName, Email, Password)
SELECT TOP (10000) UserId, UserName, Email, 'password'
FROM Users;
所以这就是查询语句:
So this is the query:
SELECT *
FROM #Users;
如果不指定任何细节,这将执行索引扫描。

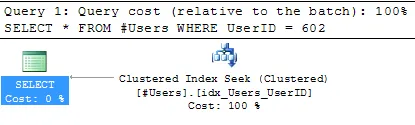
现在,如果我们指定UserId,它将查找您的聚集索引(我们将UserId作为键):
SELECT *
FROM #Users
WHERE UserID = 602;
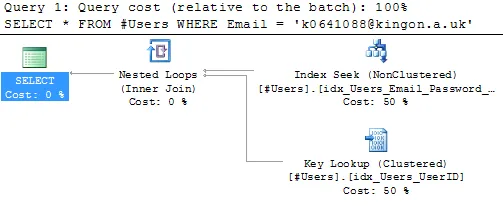
现在让我们创建一个没有包含列的索引并查询一些内容:
CREATE NONCLUSTERED INDEX idx_Users_Email_Password
ON #Users (Email, Password);
SELECT *
FROM #Users
WHERE Email = 'k0641088@kingon.a.uk';
正如我所讲,它使用已创建的索引并进行关键字查找,找到匹配的电子邮件和密码,并在表中查找其余列以输出它们(P.S.如果您只需要输出电子邮件,它不会进行关键字查找,也不需要它):
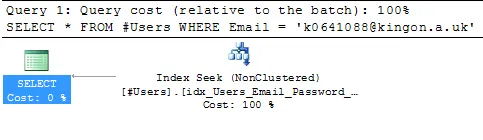
现在让我们创建一个包含UserName的索引并运行上面的查询。它将生成这个漂亮的执行计划,只需普通的NonClustered索引查找,就像我之前说过的:
CREATE NONCLUSTERED INDEX idx_Users_Email_Password_iUserName
ON #Users (Email, Password)
INCLUDE (UserName);
这是一篇高质量的文章,我建议阅读它:https://www.simple-talk.com/sql/performance/index-selection-and-the-query-optimizer/
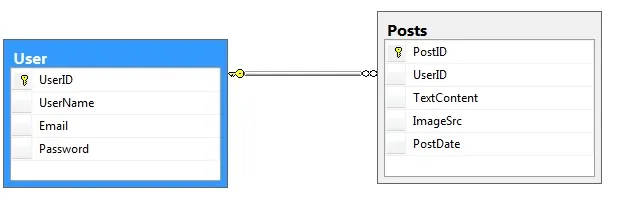
UserID是您的聚集索引,您不应该包含它。当然,您可以尝试两种方法。 - Evaldas Buinauskas