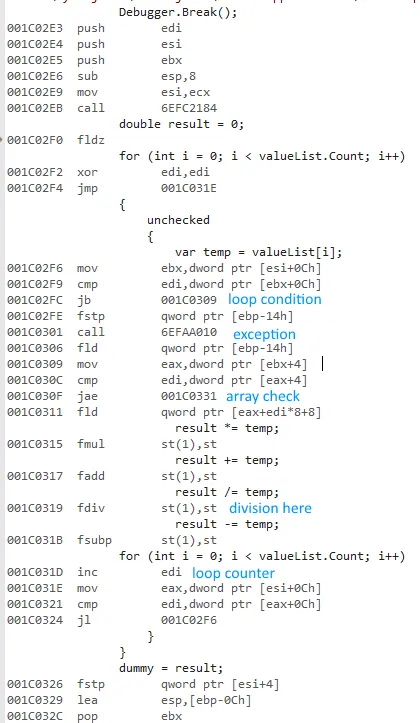
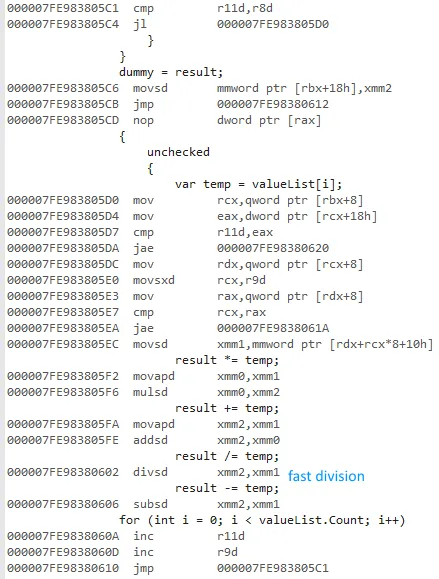
我试图测量使用 for 和 foreach 访问值类型和引用类型列表时的差异。
我使用以下类进行分析。
public static class Benchmarker
{
public static void Profile(string description, int iterations, Action func)
{
Console.Write(description);
// Warm up
func();
Stopwatch watch = new Stopwatch();
// Clean up
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
watch.Start();
for (int i = 0; i < iterations; i++)
{
func();
}
watch.Stop();
Console.WriteLine(" average time: {0} ms", watch.Elapsed.TotalMilliseconds / iterations);
}
}
我在我的值类型中使用了double。我创建了这个“假类”来测试引用类型:
class DoubleWrapper
{
public double Value { get; set; }
public DoubleWrapper(double value)
{
Value = value;
}
}
最后我运行了这段代码并比较了时间差异。
static void Main(string[] args)
{
int size = 1000000;
int iterationCount = 100;
var valueList = new List<double>(size);
for (int i = 0; i < size; i++)
valueList.Add(i);
var refList = new List<DoubleWrapper>(size);
for (int i = 0; i < size; i++)
refList.Add(new DoubleWrapper(i));
double dummy;
Benchmarker.Profile("valueList for: ", iterationCount, () =>
{
double result = 0;
for (int i = 0; i < valueList.Count; i++)
{
unchecked
{
var temp = valueList[i];
result *= temp;
result += temp;
result /= temp;
result -= temp;
}
}
dummy = result;
});
Benchmarker.Profile("valueList foreach: ", iterationCount, () =>
{
double result = 0;
foreach (var v in valueList)
{
var temp = v;
result *= temp;
result += temp;
result /= temp;
result -= temp;
}
dummy = result;
});
Benchmarker.Profile("refList for: ", iterationCount, () =>
{
double result = 0;
for (int i = 0; i < refList.Count; i++)
{
unchecked
{
var temp = refList[i].Value;
result *= temp;
result += temp;
result /= temp;
result -= temp;
}
}
dummy = result;
});
Benchmarker.Profile("refList foreach: ", iterationCount, () =>
{
double result = 0;
foreach (var v in refList)
{
unchecked
{
var temp = v.Value;
result *= temp;
result += temp;
result /= temp;
result -= temp;
}
}
dummy = result;
});
SafeExit();
}
我选择了 Release 和 Any CPU 选项,运行程序后得到了以下时间:
valueList for: average time: 483,967938 ms
valueList foreach: average time: 477,873079 ms
refList for: average time: 490,524197 ms
refList foreach: average time: 485,659557 ms
Done!
然后我选择了Release和x64选项,运行程序并得到了以下结果:
valueList for: average time: 16,720209 ms
valueList foreach: average time: 15,953483 ms
refList for: average time: 19,381077 ms
refList foreach: average time: 18,636781 ms
Done!
x64位版本为什么会快这么多?我本来期望有一些差异,但没想到会这么大。
我没有其他电脑可以使用。你能否在你的电脑上运行并告诉我结果?我正在使用Visual Studio 2015,并且我的处理器是英特尔Core i7 930。
这里是SafeExit()方法,这样你就可以自己编译和运行:
private static void SafeExit()
{
Console.WriteLine("Done!");
Console.ReadLine();
System.Environment.Exit(1);
}
按要求,使用 double? 替代我的 DoubleWrapper:
任意 CPU
valueList for: average time: 482,98116 ms
valueList foreach: average time: 478,837701 ms
refList for: average time: 491,075915 ms
refList foreach: average time: 483,206072 ms
Done!
x64
valueList for: average time: 16,393947 ms
valueList foreach: average time: 15,87007 ms
refList for: average time: 18,267736 ms
refList foreach: average time: 16,496038 ms
Done!
最后但同样重要的是:创建一个x86配置文件,可以让我获得几乎与使用Any CPU相同的结果。