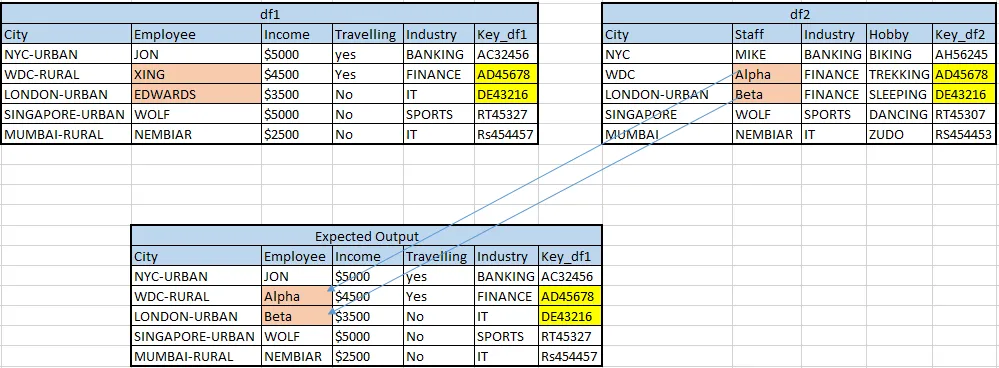
我有一个DataFrame,称为df1,它除了“员工”列外,所有列都是正确的。还有另一个DataFrame,称为df2,其中包含正确的员工姓名,但存储在“职员”列中。我正在尝试基于各自的DataFrames中的“key_df1”和“key_df2”更新df1。需要一些帮助来解决这个问题。(请参见下面图像中的预期输出)
data1=[['NYC-URBAN','JON','$5000','yes','BANKING','AC32456'],['WDC-RURAL','XING','$4500','Yes','FINANCE','AD45678'],['LONDON-URBAN','EDWARDS','$3500','No','IT','DE43216'],
['SINGAPORE-URBAN','WOLF','$5000','No','SPORTS','RT45327'],['MUMBAI-RURAL','NEMBIAR','$2500','No','IT','Rs454457']]
data2=[['NYC','MIKE','BANKING','BIKING','AH56245'],['WDC','ALPHA','FINANCE','TREKKING','AD45678'],
['LONDON-URBAN','BETA','FINANCE','SLEEPING','DE43216'],['SINGAPORE','WOLF','SPORTS','DANCING','RT45307'],
['MUMBAI','NEMBIAR','IT','ZUDO','RS454453']]
List1=['City','Employee', 'Income','Travelling','Industry', 'Key_df1']
List2=['City','Staff','Industry','Hobby', 'Key_df1']
df1=pd.DataFrame(data1,columns=List1)
df2=pd.DataFrame(data2,columns=List2)
预期输出:
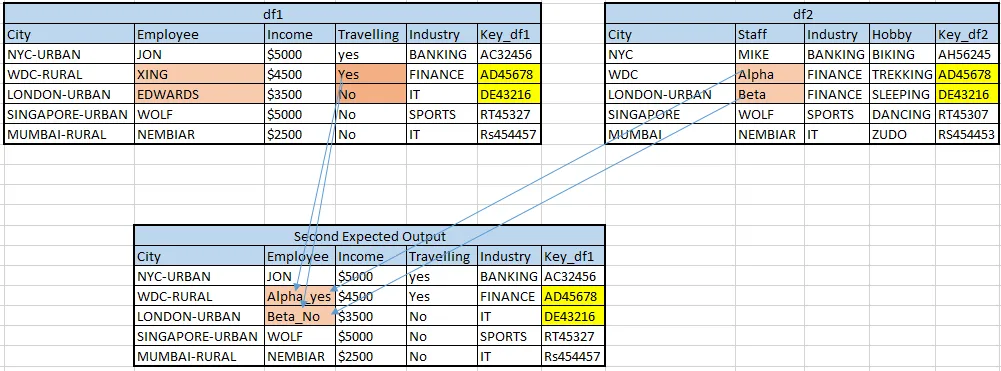
编辑(附加查询):
感谢回复。除了上述问题外,我想将“df1”的“Employee”列的值与“Travelling”列连接起来,只针对两个数据框中“Key_df1”和“Key_df2”相等的行。请参见下面的第二个预期输出。