考虑一个三类分类问题,具有以下混淆矩阵。
我使用的公式是:
在Matlab中的实现方式是:
cm_matrix =
predict_class1 predict_class2 predict_class3
______________ ______________ ______________
Actual_class1 2000 0 0
Actual_class2 34 1966 0
Actual_class3 0 0 2000
Multi-Class Confusion Matrix Output
TruePositive FalsePositive FalseNegative TrueNegative
____________ _____________ _____________ ____________
Actual_class1 2000 34 0 3966
Actual_class2 1966 0 34 4000
Actual_class3 2000 0 0 4000
我使用的公式是:
Accuracy Of Each class=(TP ./total instances of that class)
(基于这里的答案制定公式:各类别准确率计算混淆)
Sensitivity=TP./TP+FN ;
在Matlab中的实现方式是:
acc_1 = 100*(cm_matrix(1,1))/sum(cm_matrix(1,:)) = 100*(2000)/(2000+0+0) = 100
acc_2 = 100*(cm_matrix(2,2))/sum(cm_matrix(2,:)) = 100*(1966)/(34+1966+0) = 98.3
acc_3 = 100*(cm_matrix(3,3))/sum(cm_matrix(3,:)) = 100*(2000)/(0+0+2000) = 100
sensitivity_1 = 2000/(2000+0)=1 = acc_1
sensitivity_2 = 1966/(1966+34) = 98.3 = acc_2
sensitivity_3 = 2000/2000 = 1 = acc_3
问题1) 我计算每个类别的准确率公式是否正确?为了计算每个单独类别的准确率,例如正类,我应该在分子中取TP。同样地,对于只有负类的准确率,我应该在计算准确率公式的分子中考虑TN。这个公式是否适用于二元分类?我的实现是否正确?
问题2) 我的敏感度公式是否正确?为什么我得到与单个类别准确率相同的答案?
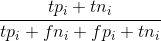
TP+TN / TP+TN+FP+FN。 - beaker正确预测的数量/样本总数。如果需要计算单个类别的准确率,则应该只考虑:类别1中正确预测的数量/类别中的样本数,其他类别同理。我认为这个公式可以扩展到多类情况,因为我最终找到了一个工具箱。但是该工具箱存在两个问题:https://www.mathworks.com/matlabcentral/fileexchange/60900-multi-class-confusion-matrix。 - Sm1