你好,我正在尝试使用Python Pandas中的字典来重新映射数据框,但我需要使用正则表达式使其正常工作。
这是字典的示例:
di_cities = {
"Ain Salah (town)": "Ain Salah"
"Agadez town": "Agadez"
"Bamako city": "Bamako",
"Birnin Konni town": "Birni N Konni",
"Konni": "Birni N Konni",
"Kadunà": "Kaduna",
"Kaduna (city)": "Kaduna",
"Kano (city)": "Kano"
"Matamey": "Matamey",
"Mopti city": "Mopti"
"N'guigmi": "Nguigmi",
"Tunis": "Tunis",
"Tunis (city)": "Tunis"
}
我使用这个迭代:
di_cities = {rf"\b{k}\b": v for k, v in di_cities.items()}
df_cities_clean = df.replace(di_cities, regex=True)
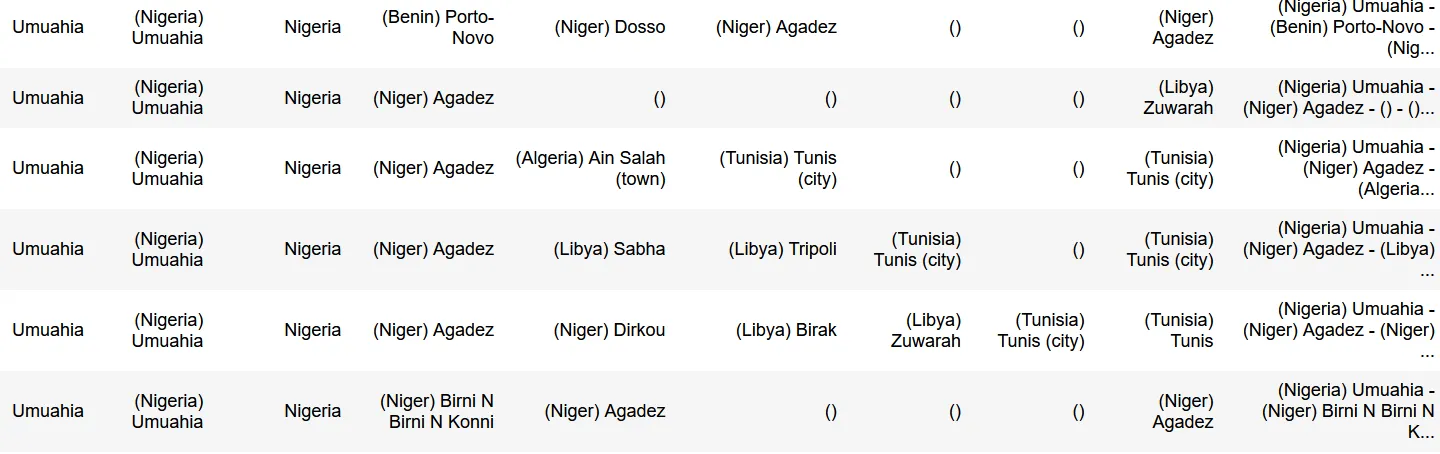
如图所示(最终结果),它适用于巴马科、阿加德兹、莫普提和每个单词字符串,但对于任何带括号的字符串都不起作用,在Birnin Konni的情况下会有些混乱。
我正在以类似的方式使用另一个字典,但那里每个字符串都在括号中,{rf"\({k}\)"可以完美地工作。
你能帮我吗?
{kind=link}
di_cities = {rf"\b{re.escape(k)}(?:(?<=\w)\b|(?<!\w))": v for k, v in di_cities.items()}。请注意,如果您的字典具有重叠键(即其他键的前缀),则可能无法正常工作。这还假定您的键始终以单词字符开头。 - Wiktor Stribiżew@用户名以通知该用户您的反馈。 - Wiktor Stribiżew