我正在努力理解CoreML。作为一个入门模型,我已经下载了Yahoo's Open NSFW caffemodel。您提供一张图片,它会给出一个概率分数(介于0和1之间),表示该图像是否包含不适当的内容。
使用coremltools,我已将该模型转换为.mlmodel并引入我的应用程序中。它在Xcode中显示如下:
使用coremltools,我已将该模型转换为.mlmodel并引入我的应用程序中。它在Xcode中显示如下:
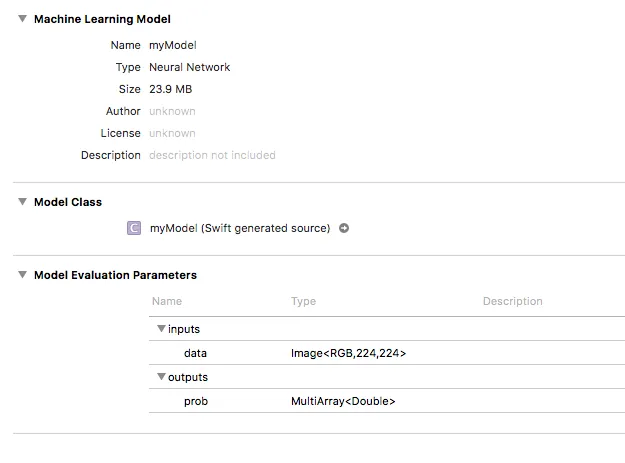
在我的应用程序中,我可以成功传递一张图片,输出出现为MLMultiArray。 我遇到的问题是如何使用此MLMultiArray来获取我的概率分数。我的代码如下:
func testModel(image: CVPixelBuffer) throws {
let model = myModel()
let prediction = try model.prediction(data: image)
let output = prediction.prob // MLMultiArray
print(output[0]) // 0.9992402791976929
print(output[1]) // 0.0007597212097607553
}
作为参考,CVPixelBuffer被调整大小到模型要求的224x224(一旦我弄清楚这个问题,我就会开始使用Vision)。
如果我提供不同的图像,则我打印到控制台的两个索引确实会改变,但它们的得分与在Python中运行模型时得到的结果大相径庭。当在Python中测试通过相同模型传递的图像时,输出是0.16,而我的CoreML输出(如上例所示)与我期望看到的迥然不同(是一个字典,而不是Python的双重输出)。
需要进行更多的工作才能获得我期望的结果吗?