我需要编写一个简单的 Fibonacci 算法实现,并且优化它的速度。
这是我的初始实现:
public class Fibonacci {
public static long getFibonacciOf(long n) {
if (n== 0) {
return 0;
} else if (n == 1) {
return 1;
} else {
return getFibonacciOf(n-2) + getFibonacciOf(n-1);
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner (System.in);
while (true) {
System.out.println("Enter n :");
long n = scanner.nextLong();
if (n >= 0) {
long beginTime = System.currentTimeMillis();
long fibo = getFibonacciOf(n);
long endTime = System.currentTimeMillis();
long delta = endTime - beginTime;
System.out.println("F(" + n + ") = " + fibo + " ... computed in " + delta + " milliseconds");
} else {
break;
}
}
}
}
如您所见,我正在使用System.currentTimeMillis()来获得计算斐波那契数列所需时间的简单测量。
随着你在下面这张图片中看到的,这个实现变得越来越慢
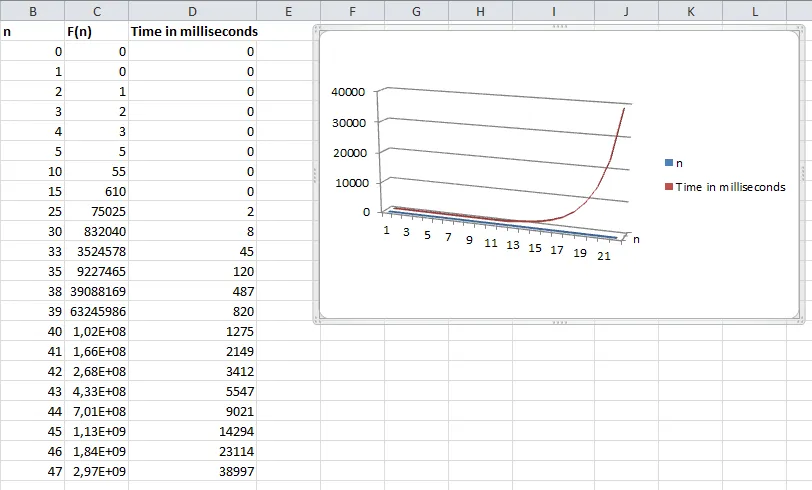
因此,我有一个简单的优化想法。将前面的值放入HashMap中,并且不再每次重新计算它们,而是直接从HashMap中获取它们(如果存在)。如果它们不存在,则将它们放入HashMap中。
以下是新版本的代码:
public class FasterFibonacci {
private static Map<Long, Long> previousValuesHolder;
static {
previousValuesHolder = new HashMap<Long, Long>();
previousValuesHolder.put(Long.valueOf(0), Long.valueOf(0));
previousValuesHolder.put(Long.valueOf(1), Long.valueOf(1));
}
public static long getFibonacciOf(long n) {
if (n== 0) {
return 0;
} else if (n == 1) {
return 1;
} else {
if (previousValuesHolder.containsKey(Long.valueOf(n))) {
return previousValuesHolder.get(n);
} {
long newValue = getFibonacciOf(n-2) + getFibonacciOf(n-1);
previousValuesHolder.put(Long.valueOf(n), Long.valueOf(newValue));
return newValue;
}
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner (System.in);
while (true) {
System.out.println("Enter n :");
long n = scanner.nextLong();
if (n >= 0) {
long beginTime = System.currentTimeMillis();
long fibo = getFibonacciOf(n);
long endTime = System.currentTimeMillis();
long delta = endTime - beginTime;
System.out.println("F(" + n + ") = " + fibo + " ... computed in " + delta + " milliseconds");
} else {
break;
}
}
}
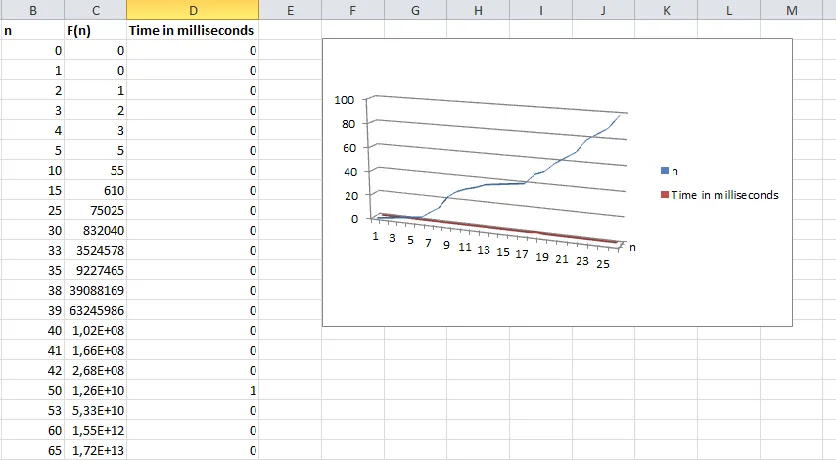
[编辑说明:]尽管这个问题解决了我的问题,但是从上面可以看出我还有其他问题。
BigInteger代替长整型作为斐波那契数列的数据类型。 - MinecraftShamrock