这就是我提出这个问题的原因: 去年我编写了一些C++代码来计算一种特定类型模型(由贝叶斯网络描述)的后验概率。该模型工作得很好,其他人开始使用我的软件。现在我想改进我的模型。由于我已经为新模型编写了略有不同的推理算法,所以我决定使用Python,因为运行时间不是关键,而且Python可能让我编写更优雅和易于管理的代码。
通常在这种情况下,我会搜索已有的Python贝叶斯网络包,但是我所使用的推理算法是自己编写的,而且我认为这也是学习Python良好设计的绝佳机会。
我已经找到了一个非常好的用于网络图的Python模块(networkx),它允许您将字典附加到每个节点和每条边。基本上,这可以让我给节点和边属性。
对于特定网络及其观察数据,我需要编写一个函数来计算模型中未分配变量的似然性。
例如,在经典的“Asia”网络(http://www.bayesserver.com/Resources/Images/AsiaNetwork.png)中,"XRay Result"和"Dyspnea"状态已知,我需要编写一个函数来计算其他变量具有某些值的概率(根据某个模型)。
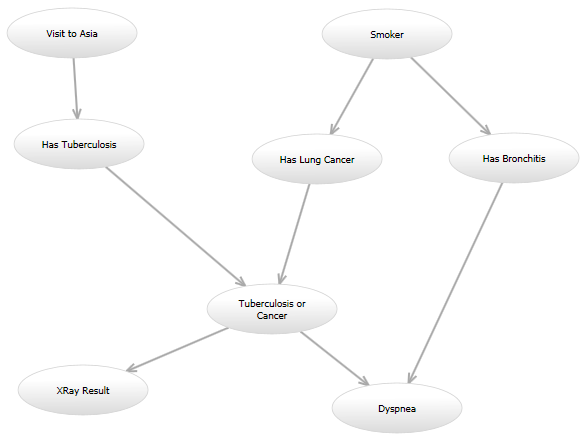{kind=link}
这是我的编程问题: 我打算尝试几个模型,在未来可能会尝试另一个模型。例如,一个模型可能看起来与Asia网络完全相同。在另一个模型中,可能会从“Visit to Asia”指向“Has Lung Cancer”的有向边添加。另一个模型可能使用原始有向图,但“Tuberculosis or Cancer”和“Has Bronchitis”节点给出“Dyspnea”节点的概率模型可能不同。所有这些模型都将以不同的方式计算似然性。
所有模型都会有很大的重叠;例如,多个边进入一个 "Or" 节点,如果所有输入都是 "0",则将始终产生 "0",否则为 "1"。但是有些模型将具有在某个范围内取整数值的节点,而其他模型将是布尔值。以前我曾苦恼如何编写此类内容。我不想撒谎;代码被复制并粘贴了不少,有时我需要将单个方法的更改传播到多个文件中。这一次,我真的希望花时间用正确的方式来做这件事。
几个选项:
- 我已经按照正确的方式进行了此操作。先编写代码,后提问。将代码复制并粘贴,并为每个模型创建一个类会更快。世界是一个黑暗而杂乱无序的地方...
- 每个模型都是自己的类,同时也是通用 BayesianNetwork 模型的子类。这个通用模型将使用一些将被覆盖的函数。斯特鲁斯特鲍尔德会为此感到自豪。
- 在同一个类中创建多个函数来计算不同的可能性。
- 编写通用 BayesianNetwork 库,并将我的推理问题实现为由该库读取的特定图形。节点和边应给出像“布尔”和“OrFunction”这样的属性,这些属性可以在已知父节点状态的情况下用于计算不同结果的概率。这些属性字符串(如 "OrFunction")甚至可以用于查找并调用正确的函数。也许几年后我会制作类似于 Mathematica 1988 版本的东西!
更新:面向对象的思想在这里非常有帮助(每个节点都有一组指定的先驱节点,具有某个节点子类型,并且每个节点都有一个可能性函数,该函数计算其在给定前任节点的状态下的不同结果状态的可能性等)。面向对象编程真是太棒了!