我正在制作一个计算器,作为学习Python、Pandas和Numpy的有趣项目,用于确定应该喂什么食物给鱼。
我的数据组织如下:
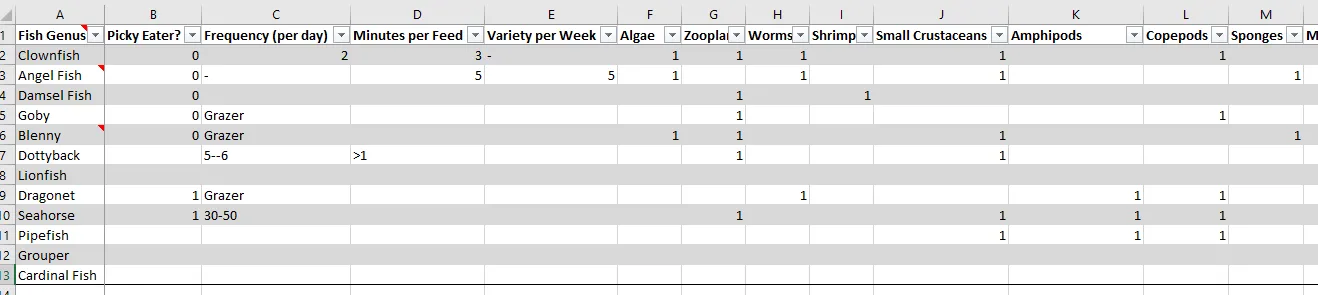
如您所见,我的鱼是行,不同的食物是列。
我希望做的是,让用户(即我)输入一种食物,并让程序输出所有那些值不为nan的内容。
我之所以选择将它们保留为“nan”而不是“0”,是因为我在不同的位置使用不同的数字来表示喜好。1是自然食物,2是可以但不理想,3是只吃活鱼。
有没有办法使用Pandas做到这一点? 我在网上搜索到的信息都是帮助我筛选出列中的行,但很难找到关于筛选行中的列的信息。
目前,我的代码看起来像这样:
import pandas as pd
import numpy as np
df = pd.read_excel(r'C:\Users\Daniel\OneDrive\Documents\AquariumAiMVP.xlsx')
clownfish = df[0:1]
angelfish = df[1:2]
damselfish = df[2:3]
所以,正如您所看到的,我还没有真正取得任何进展。我尝试使用以下方法过滤掉空值:
clownfish_wild_diet = pd.isnull(df.clownfish)
但结果会出现错误,提示:
AttributeError: 'DataFrame'对象没有'clownfish'属性
谢谢大家的帮助。我是一名完全的Pandas新手,非常感激。