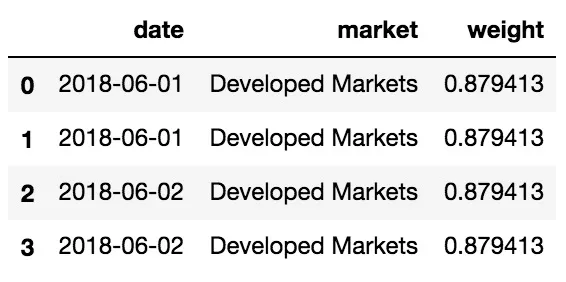
我正在阅读以下JSON结构:
{"response":
{"GDUEACWF":
{"2018-06-01":
[{"groupwide_market":"Developed Markets",
"weights":0.8794132316432903},
{"groupwide_market":"Developed Markets",
"weights":0.8794132316432903}],
"2018-06-02":
[{"groupwide_market":"Developed Markets",
"weights":0.8794132316432903},
{"groupwide_market":"Developed Markets",
"weights":0.8794132316432903}]}}}
并且试图将其转换为以下格式的Pandas数据框。
|data_date |groupwide_market |weights
|2018-06-01 |Developed Markets |0.08794132316432903
我尝试通过使用以下代码循环遍历每个k,v对中的每个列表来实现此操作。虽然确实可以工作,但速度非常慢。100k行数据需要超过30分钟来生成。
df = pd.DataFrame()
#concatenating each line of the list within each dict cell
for k1,v1 in data['response'][mnemonic].items():
for ele in v1:
df_temp = pd.concat({k2: pd.Series(v2) for k2, v2 in ele.items()}).transpose()
df_temp['data_date'] = k1
df = df.append(df_temp,ignore_index=True)
df.columns = [x[0] for x in df.columns]
请问是否有更高效的方法来做这件事?我已经阅读了json_normalize的文档和示例,但无法在此情况下找出如何应用它。谢谢!