我从tesseract中提取了一个图像文档,并成功地进行了提取。但是我无法理解提取文档的坐标。
问题描述:-
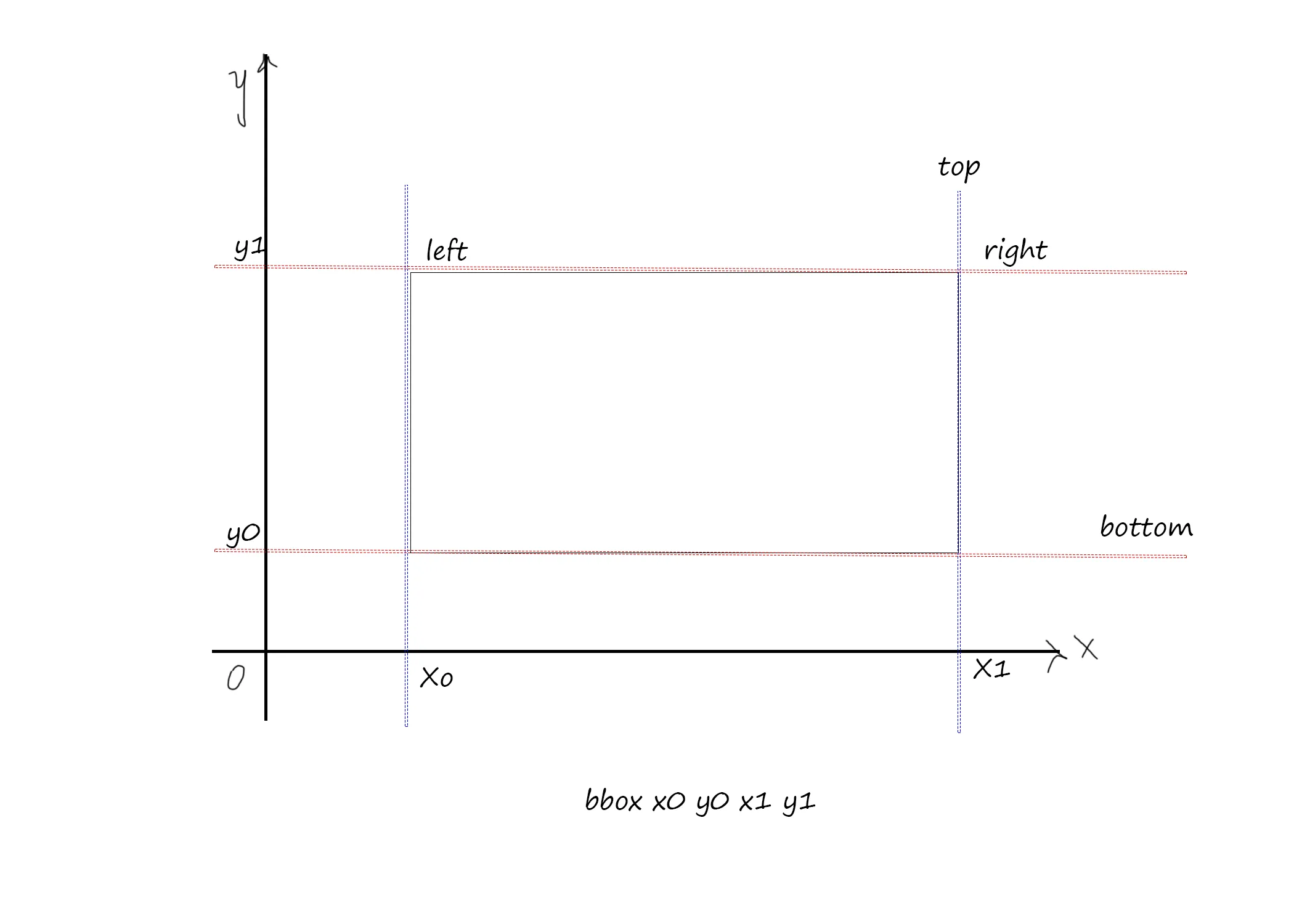
它显示坐标,但请告诉我这些坐标是否表示像素或其他内容。这些坐标有四个,类似于 title="bbox 10 13 43 46",那么10、13、43和46是什么意思?它们代表什么位置?
提取后的完整代码
问题描述:-
它显示坐标,但请告诉我这些坐标是否表示像素或其他内容。这些坐标有四个,类似于 title="bbox 10 13 43 46",那么10、13、43和46是什么意思?它们代表什么位置?
提取后的完整代码
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>
</title>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<meta name='ocr-system' content='tesseract'/>
</head>
<body>
<div class='ocr_page' id='page_1' title='image "D:\ABC.tif"; bbox 0 0 464 101'>
<div class='ocr_carea' id='block_1_1' title="bbox 10 13 330 55">
<p 1class='ocr_par'>
<span class='ocr_line' id='line_1_1' title="bbox 10 13 330 55">
<span class='ocr_word' id='word_1_1' title="bbox 10 13 43 46">
<span class='ocrx_word' id='xword_1_1' title="x_wconf -1"><strong>hi</strong></span>
</span>
<span class='ocr_word' id='word_1_2' title="bbox 148 13 268 47">
<span class='ocrx_word' id='xword_1_2' title="x_wconf -1"><strong>whats</strong></span>
</span>
<span class='ocr_word' id='word_1_3' title="bbox 283 22 330 55">
<span class='ocrx_word' id='xword_1_3' title="x_wconf -1"><strong>up</strong></span>
</span>
</span>
</p>
</div>
</div>
</body>
</html>