在pandas数据帧中,我使用以下代码绘制一列的直方图:
my_df.hist(column = 'field_1')
在pyspark数据框中是否有可以实现相同目标的东西?(我在Jupyter Notebook中)谢谢!
在pandas数据帧中,我使用以下代码绘制一列的直方图:
my_df.hist(column = 'field_1')
在pyspark数据框中是否有可以实现相同目标的东西?(我在Jupyter Notebook中)谢谢!
很遗憾,我认为在PySpark Dataframes API中没有干净的plot()或hist()函数,但我希望事情最终会朝着这个方向发展。
目前,您可以在Spark中计算直方图,并将计算出的直方图作为条形图绘制。例如:
import pandas as pd
import pyspark.sql as sparksql
# Let's use UCLA's college admission dataset
file_name = "https://stats.idre.ucla.edu/stat/data/binary.csv"
# Creating a pandas dataframe from Sample Data
df_pd = pd.read_csv(file_name)
sql_context = sparksql.SQLcontext(sc)
# Creating a Spark DataFrame from a pandas dataframe
df_spark = sql_context.createDataFrame(df_pd)
df_spark.show(5)
这就是数据的样子:
Out[]: +-----+---+----+----+
|admit|gre| gpa|rank|
+-----+---+----+----+
| 0|380|3.61| 3|
| 1|660|3.67| 3|
| 1|800| 4.0| 1|
| 1|640|3.19| 4|
| 0|520|2.93| 4|
+-----+---+----+----+
only showing top 5 rows
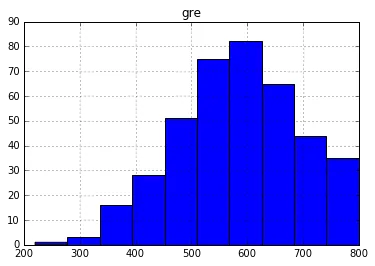
# This is what we want
df_pandas.hist('gre');
# Doing the heavy lifting in Spark. We could leverage the `histogram` function from the RDD api
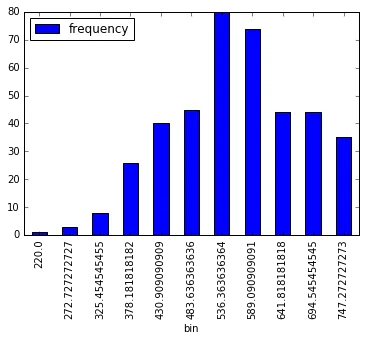
gre_histogram = df_spark.select('gre').rdd.flatMap(lambda x: x).histogram(11)
# Loading the Computed Histogram into a Pandas Dataframe for plotting
pd.DataFrame(
list(zip(*gre_histogram)),
columns=['bin', 'frequency']
).set_index(
'bin'
).plot(kind='bar');
from pyspark_dist_explore import hist
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
hist(ax, my_df.select('field_1'), bins = 20, color=['red'])
本库使用rdd直方图函数来计算bin值。
display(fig)。 - Cherry Wuimport pyspark.sql.functions as F
import pyspark.sql as SQL
win = SQL.Window.partitionBy('column_of_values')
df.select(F.count('column_of_values').over(win).alias('histogram'))
聚合操作在集群的每个分区上执行,不需要向主机进行额外的往返。partitionBy需要一个分组依据或其他东西的分区,你不能使用它来动态生成直方图箱。 - Mehdi LAMRANIhistogram方法用于RDD,返回区间范围和区间计数。以下是一个函数,它将这个直方图数据作为直方图绘制。
import numpy as np
import matplotlib.pyplot as mplt
import matplotlib.ticker as mtick
def plotHistogramData(data):
binSides, binCounts = data
N = len(binCounts)
ind = np.arange(N)
width = 1
fig, ax = mplt.subplots()
rects1 = ax.bar(ind+0.5, binCounts, width, color='b')
ax.set_ylabel('Frequencies')
ax.set_title('Histogram')
ax.set_xticks(np.arange(N+1))
ax.set_xticklabels(binSides)
ax.xaxis.set_major_formatter(mtick.FormatStrFormatter('%.2e'))
ax.yaxis.set_major_formatter(mtick.FormatStrFormatter('%.2e'))
mplt.show()
aggData.select(columnName).rdd.flatMap(lambda x: x).histogram(10) 进行工作。问题是:如何在x轴上绘制每个bin内的平均值,而不是bin值(1,2,3,...)? - dierrebins = 10
df.withColumn("factor", F.expr("round(field_1/bins)*bins")).groupBy("factor").count()
bins”,因为给定的输入列是:[field_1];第1行第19个位置。 - nigelhenrydef pyspark_histogram(df, col, group=None, nbins=100, binn=None):
if not group:
group = []
w = Window.partitionBy(group)
df = (
df
.withColumn("hist_div", F.lit(binn) if binn else (F.max(col).over(w)-F.min(col).over(w))/nbins)
.withColumn(col, F.floor(F.col(col)/F.col("hist_div"))*F.col("hist_div"))
.groupBy(group + [col])
.agg(F.count("*").alias("count"))
.withColumn("sum", F.sum("count").over(w))
.withColumn("percent(%)", F.round(F.col("count")*100.0/F.col("sum"), 1))
.drop("sum")
.orderBy(group + [col])
)
return df
这很简单,而且运行良好。
df.groupby(
'<group-index>'
).count().select(
'count'
).rdd.flatMap(
lambda x: x
).histogram(20)
import pyspark.sql.functions as f
def plotHist(df, variable, minValue, maxValue, bins = 10):
factor = bins / (maxValue - minValue + 1)
(
df.withColumn('cappedValue', f.least(f.lit(maxValue), f.greatest(f.lit(minValue), variable)))
.withColumn('buckets', f.round(((f.col('cappedValue')) - minValue)*factor)/factor + minValue)
.groupBy('buckets').count().display()
)
{kind=link}
{kind=link}
zip迭代器生成数据帧时,出现了错误。鉴于pyspark直方图,使用pd.DataFrame(list(zip(*gre_histogram)), columns=['bin', 'frequency'])创建pandas数据帧更加简洁,并且对我有效。 - Sohan JainDataFrame,没有使用 RDD 的经验。为什么在这里需要应用flatMap()? - Konstantin