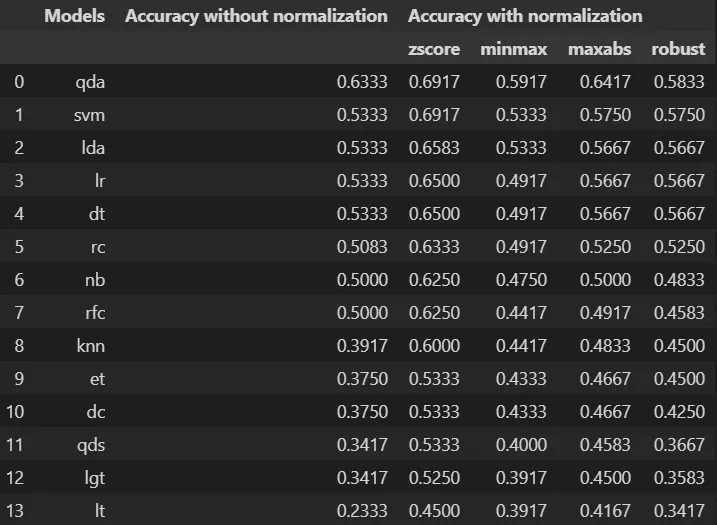
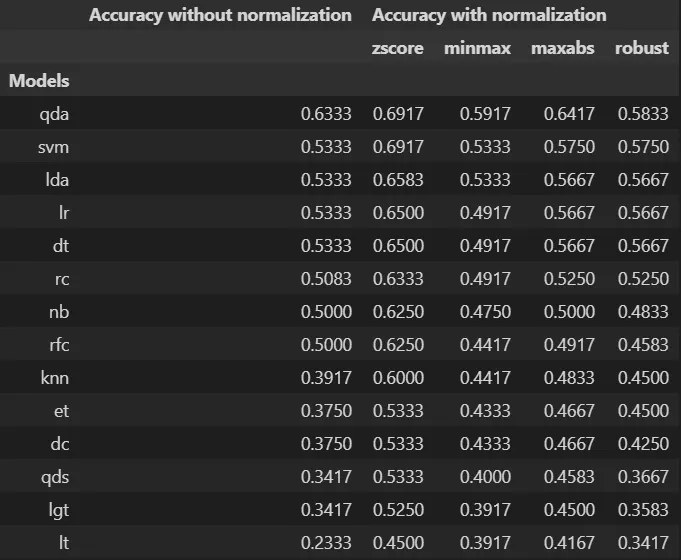
我有三列数据,分别为模型(应该作为索引),不使用标准化的准确率,以及采用标准化的准确率(使用zscore、minmax、maxabs、robust),需要按照以下格式创建:
------------------------------------------------------------------------------------
| Models | Accuracy without normalization | Accuracy with normalization |
| | |-----------------------------------|
| | | zscore | minmax | maxabs | robust |
------------------------------------------------------------------------------------
dfmod-> Models column
dfacc-> Accuracy without normalization
dfacc1-> Accuracy with normalization - zscore
dfacc2-> Accuracy with normalization - minmax
dfacc3-> Accuracy with normalization - maxabs
dfacc4-> Accuracy with normalization - robust
dfout=pd.DataFrame({('Accuracy without Normalization'):{dfacc},
('Accuracy using Normalization','zscore'):{dfacc1},
('Accuracy using Normalization','minmax'):{dfacc2},
('Accuracy using Normalization','maxabs'):{dfacc3},
('Accuracy using Normalization','robust'):{dfacc4},
},index=dfmod
)
我想尝试像这样做,但我无法进一步理解。
测试数据:
qda 0.6333 0.6917 0.5917 0.6417 0.5833
svm 0.5333 0.6917 0.5333 0.575 0.575
lda 0.5333 0.6583 0.5333 0.5667 0.5667
lr 0.5333 0.65 0.4917 0.5667 0.5667
dt 0.5333 0.65 0.4917 0.5667 0.5667
rc 0.5083 0.6333 0.4917 0.525 0.525
nb 0.5 0.625 0.475 0.5 0.4833
rfc 0.5 0.625 0.4417 0.4917 0.4583
knn 0.3917 0.6 0.4417 0.4833 0.45
et 0.375 0.5333 0.4333 0.4667 0.45
dc 0.375 0.5333 0.4333 0.4667 0.425
qds 0.3417 0.5333 0.4 0.4583 0.3667
lgt 0.3417 0.525 0.3917 0.45 0.3583
lt 0.2333 0.45 0.3917 0.4167 0.3417
这些是按照上述表格中指定的顺序对应的各子列的值。