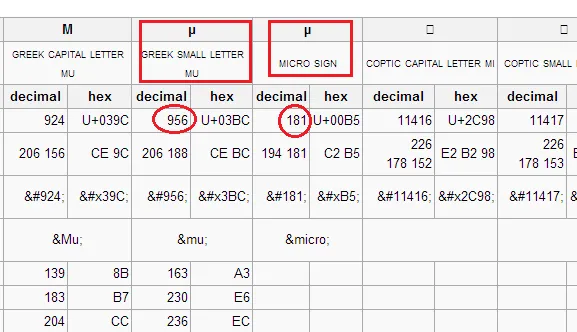
我遇到了一个令人惊讶的问题。
我在我的应用程序中加载了一个文本文件,我有一些逻辑来比较带有 µ 的值。
我意识到,即使两个文本内容相同,比较的结果也是错误的。
Console.WriteLine("μ".Equals("µ")); // returns false
Console.WriteLine("µ".Equals("µ")); // return true
后来的行中复制粘贴了字符 µ。
然而,这些可能不是唯一看起来相同但实际上不同的字符。
C# 中有没有比较这些外观相同但实际上不同的字符的方法?