在一个数据框中,我有一列字符串,它们彼此之间非常相似,只是通过%的差异来区分。我想将这些共同点字符串组合成一个单一的字符串,在每个位置上具有最常见的字符。
数据框如下:
我试图添加另一列,其中包含来自Pattern列最可能的字符串。
数据框如下:
pattern Freq score rank
DT%E 37568 1138.4242 1
%TGE 37666 1018.0000 2
D%GE 37641 1017.3243 3
DTG% 37665 965.7692 4
%VGNE 34234 684.6800 5
SVGN% 34281 634.8333 6
SV%NE 34248 634.2222 7
SVG%E 34265 623.0000 8
%LGNE 41098 595.6232 9
SL%NE 41086 595.4493 10
SLGN% 41200 564.3836 11
SPT%AYNE 35082 539.7231 12
SP%AAYNE 35094 531.7273 13
SPTA%YNE 35061 531.2273 14
SPTAA%NE 35225 518.0147 15
SPTAAYN% 35144 516.8235 16
%PTAAYNE 35111 516.3382 17
S%TAAYNE 35100 516.1765 18
SPTAAY%E 35130 509.1304 19
SLG%E 41467 450.7283 20
我试图添加另一列,其中包含来自Pattern列最可能的字符串。
pattern Freq score rank true_string
DT%E 37568 1138.4242 1 DTGE
%TGE 37666 1018.0000 2 DTGE
D%GE 37641 1017.3243 3 DTGE
DTG% 37665 965.7692 4 DTGE
%VGNE 34234 684.6800 5 SVGNE
SVGN% 34281 634.8333 6 SVGNE
SV%NE 34248 634.2222 7 SVGNE
SVG%E 34265 623.0000 8 SVGNE
%LGNE 41098 595.6232 9 SLGNE
SL%NE 41086 595.4493 10 SLGNE
SLGN% 41200 564.3836 11 SLGNE
SPT%AYNE 35082 539.7231 12 SPTAAYNE
SP%AAYNE 35094 531.7273 13 SPTAAYNE
SPTA%YNE 35061 531.2273 14 SPTAAYNE
SPTAA%NE 35225 518.0147 15 SPTAAYNE
SPTAAYN% 35144 516.8235 16 SPTAAYNE
%PTAAYNE 35111 516.3382 17 SPTAAYNE
S%TAAYNE 35100 516.1765 18 SPTAAYNE
SPTAAY%E 35130 509.1304 19 SPTAAYNE
SLG%E 41467 450.7283 20 SLGNE
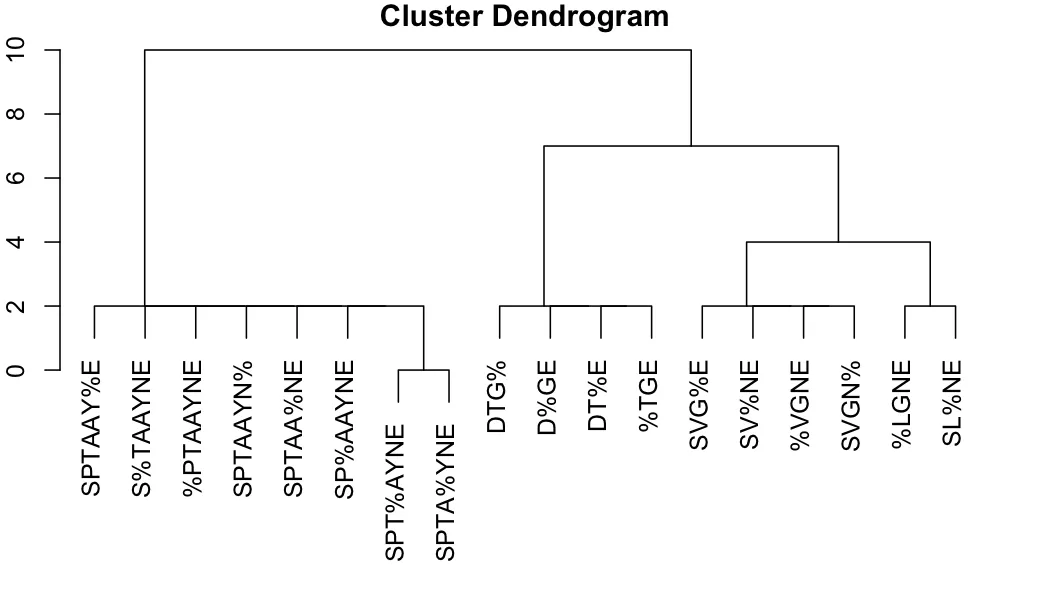
SVGNE和SLGNE似乎特别棘手。 - thelatemailS%GNE。 - Calum You