我正在尝试使用networkx创建图表,目前我已经从以下文本文件创建了节点: 文件1(user_id.txt)示例数据:
user_000001
user_000002
user_000003
user_000004
user_000005
user_000006
user_000007
文件2(user_country.txt)的示例数据:如果用户没有输入国家详细信息,则包含一些空白行。
Japan
Peru
United States
Bulgaria
Russian Federation
United States
文件 3(user_agegroup.txt)数据:包含四个年龄组
[12-18],[19-25],[26-32],[33-39]
我有另外两个文件,包含用于在图中添加边的示例数据
文件4(id,agegroup.txt)
user_000001,[19-25]
user_000002,[19-25]
user_000003,[33-39]
user_000004,[19-25]
user_000005,[19-25]
user_000006,[19-25]
user_000007,[26-32]
文件5(id,country.txt)
(user_000001,Japan)
(user_000002,Peru)
(user_000003,United States)
(user_000004,)
(user_000005,Bulgaria)
(user_000006,Russian Federation)
(user_000007,United States)
迄今为止,我已经编写了以下代码来绘制仅包含节点的图表:(请检查代码,因为print g.number_of_nodes()从未打印正确的节点数,尽管print g.nodes()显示正确的节点数。)
import csv
import networkx as nx
import matplotlib.pyplot as plt
g=nx.Graph()
#extract and add AGE_GROUP nodes in graph
f1 = csv.reader(open("user_agegroup.txt","rb"))
for row in f1:
g.add_nodes_from(row)
nx.draw_circular(g,node_color='blue')
#extract and add COUNTRY nodes in graph
f2 = csv.reader(open('user_country.txt','rb'))
for row in f2:
g.add_nodes_from(row)
nx.draw_circular(g,node_color='red')
#extract and add USER_ID nodes in graph
f3 = csv.reader(open('user_id.txt','rb'))
for row in f3:
g.add_nodes_from(row)
nx.draw_random(g,node_color='yellow')
print g.nodes()
plt.savefig("path.png")
print g.number_of_nodes()
plt.show()
除此之外,我无法想象如何从file4和file5添加边缘。 如果有代码的帮助,将不胜感激。 谢谢。
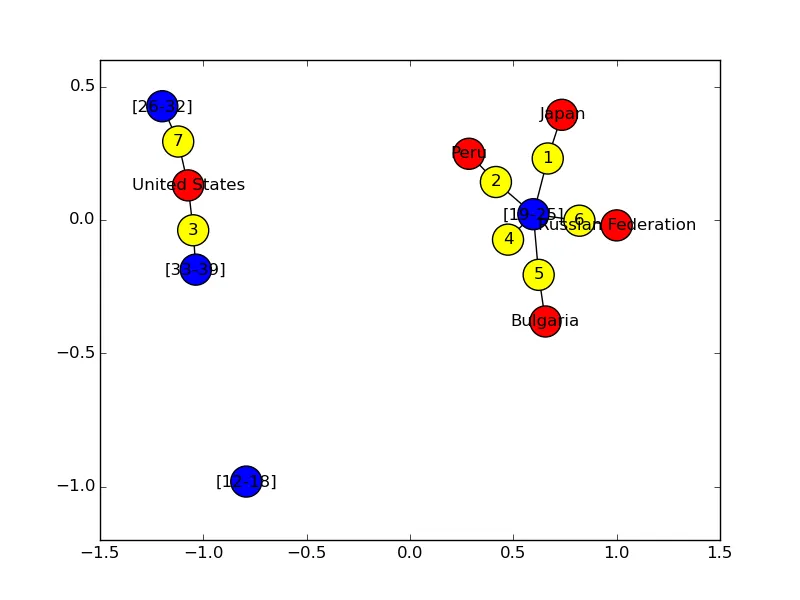
g.number_of_nodes只返回g.node(内部是一个字典)的长度,而g.nodes()也只是返回g.node。因此,除非在检查len(g.nodes())和g.number_of_nodes)之间修改了图形,否则很难看出这两个函数有什么不同。这三个文件中的所有条目都是唯一的吗?任何重复的条目将对应于相同的节点。(字典文档) - Bonlenfumg,number_of_nodes和g.number_of_edges也产生了正确的结果。 - VivekP20