我将尝试使用 dtwclust 包执行动态时间扭曲距离(DTW)的时间序列聚类。
我将使用以下函数:
dtwclust(data = NULL, type = "partitional", k = 2L, method = "average",
distance = "dtw", centroid = "pam", preproc = NULL, dc = NULL,
control = NULL, seed = NULL, distmat = NULL, ...)
我将数据保存为列表,它们具有不同的长度。 就像下面的例子一样,这是一个时间序列。
$a
[1] 0 0 0 0 2 3 6 7 8 9 11 13
$b
[1] 0 1 1 2 4 7 8 11 13 15 17 19 22 25 28 31 34 35
$c
[1] 1 2 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 6 6 6 6 7 7 8 8 9 10 10 12 14 15 17 19
$d
[1] 0 0 0 0 0 1 2 4 4 4
$e
[1] 0 1 1 3 5 6 9 12 14 17 19 20 22 24 28 31 32 34
现在,我的问题如下:
(1) 因为列表长度不同,所以我只能选择dtw、dtw2或sbd作为距离度量,以及dba、shape或pam作为质心。但是,我不知道哪种距离度量和质心是正确的。
(2) 我已经绘制了一些图形,但是我不知道如何选择正确和合理的图形。
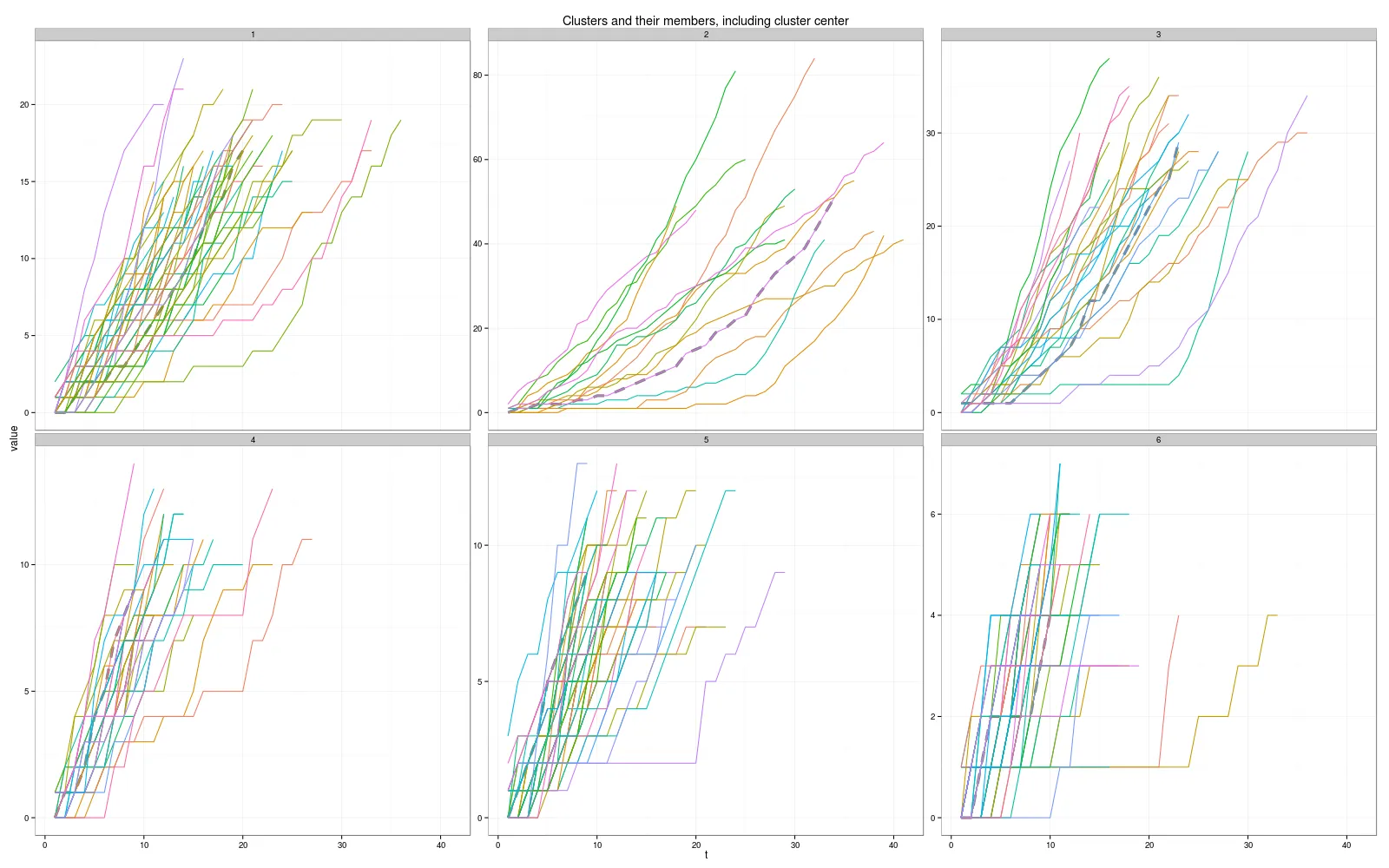
k = 6, distance = dtw, centroid = dba:
k = 4, distance = dtw, centroid = dba(聚类中心看起来奇怪?)
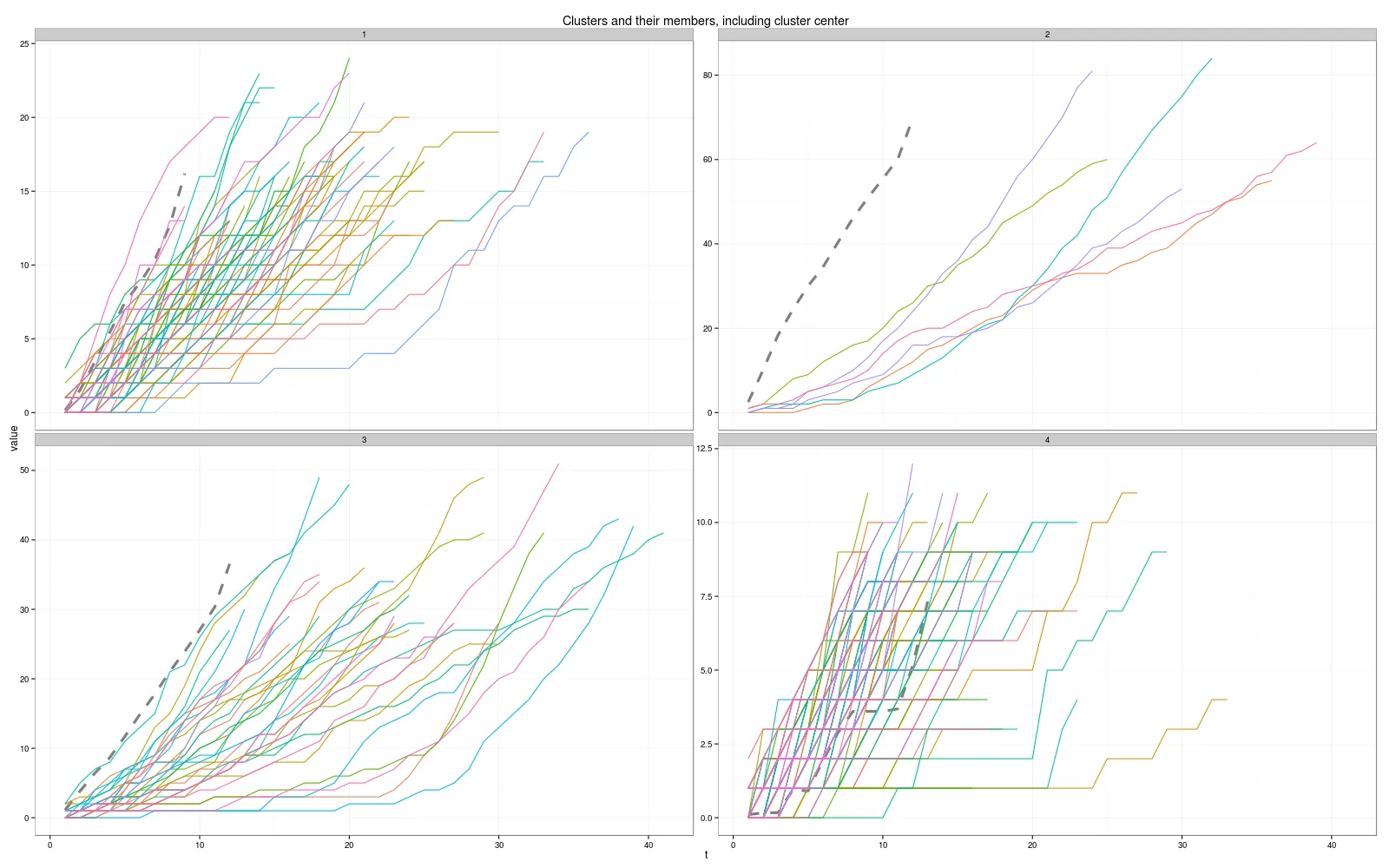
我已经尝试了所有组合,从k=4到13……但我不知道如何选择正确的组合……
dtwclust现在在cvi函数中包括评估设施。 - Alexis