我一直使用office文档成像进行OCR,以从图像中获取文本。对于这个图像:
我想知道在将其提供给OCR之前,用于改善图像质量的预处理步骤。到目前为止,我尝试了二值化(阈值),模糊(高斯),锐化,均值去除和增加图像的亮度和对比度等方法,但OCR引擎仍无法获得准确的文本(可能只有50%的成功率)。
我想知道正确顺序的预处理步骤(最好是C#),以改善图像质量。屏幕的图像是通过网络摄像头捕获的。谢谢。
我想知道在将其提供给OCR之前,用于改善图像质量的预处理步骤。到目前为止,我尝试了二值化(阈值),模糊(高斯),锐化,均值去除和增加图像的亮度和对比度等方法,但OCR引擎仍无法获得准确的文本(可能只有50%的成功率)。
我想知道正确顺序的预处理步骤(最好是C#),以改善图像质量。屏幕的图像是通过网络摄像头捕获的。谢谢。
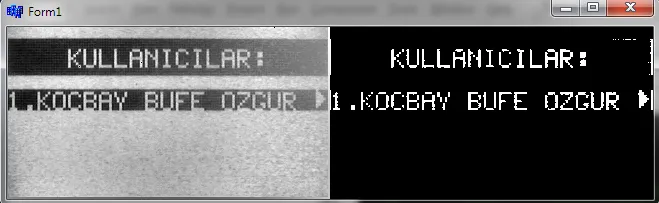
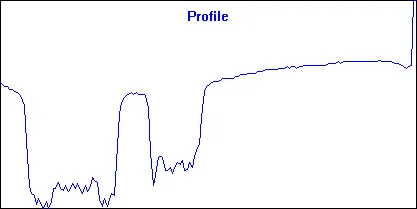
24/32位,那么每个字节就是R,G,B=<0,255>...当我使用灰度时,我只需将R,G,B相加即可得到I=R+G+B=<0,3*255=765>,以简化事情...如果您想回到RGB,则只需R=G=B=I/3;这正是我的pixel_format所做的,我的每个像素都是{ DWORD dd; DWORD dw[2]; BYTE db[4]; }的联合体,因此我可以轻松地访问像素作为32位、2x16位或4x8位值,这对应于完整的颜色、导数和r、g、b、a分量。 - Spektre