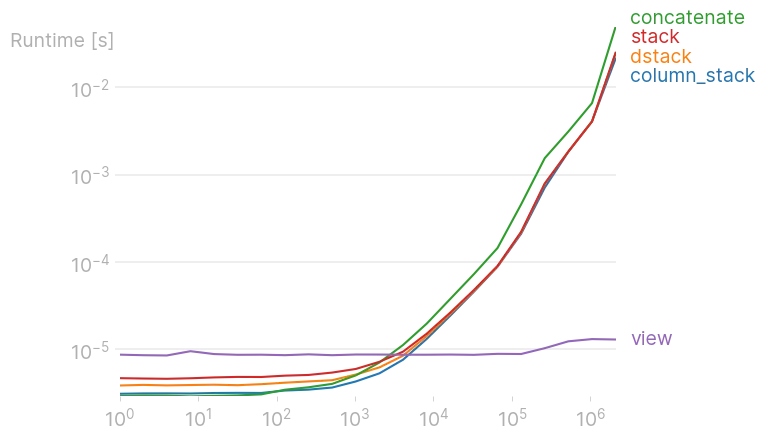
没有任何一种替代方案是本地的或可以避免重塑、转置等操作。
例如,在内部,column_stack将其输入转换为2D“列”数组。实际上它正在执行以下操作:
In [1171]: np.concatenate((np.array(u.real,ndmin=2).T,np.array(u.imag,ndmin=2).T),axis=1)
Out[1171]:
array([[ 1., 2.],
[ 2., 4.],
[ 3., 6.],
[ 4., 8.]])
vstack将其输入通过atleast_2d(m),确保每个输入都是1行2D数组。而np.dstack则使用atleast_3d(m)。
新增加的函数是np.stack
In [1174]: np.stack((u.real,u.imag),-1)
Out[1174]:
array([[ 1., 2.],
[ 2., 4.],
[ 3., 6.],
[ 4., 8.]])
它使用None索引来纠正连接的维度;有效地:
np.concatenate((u.real[:,None],u.imag[:,None]),axis=1)
所有的都最终使用np.concatenate;它和np.array是仅有的编译连接函数。
另一个技巧是使用view
In [1179]: u.view('(2,)float')
Out[1179]:
array([[ 1., 2.],
[ 2., 4.],
[ 3., 6.],
[ 4., 8.]])
复数值被保存为相邻的两个浮点数。因此,同一数据缓冲区既可以视为纯浮点数,也可以使用此视图作为浮点数的二维数组。与“concatenate”函数相比,这里没有复制。另一个对替代方案的测试是询问当u为2d或更高时会发生什么?