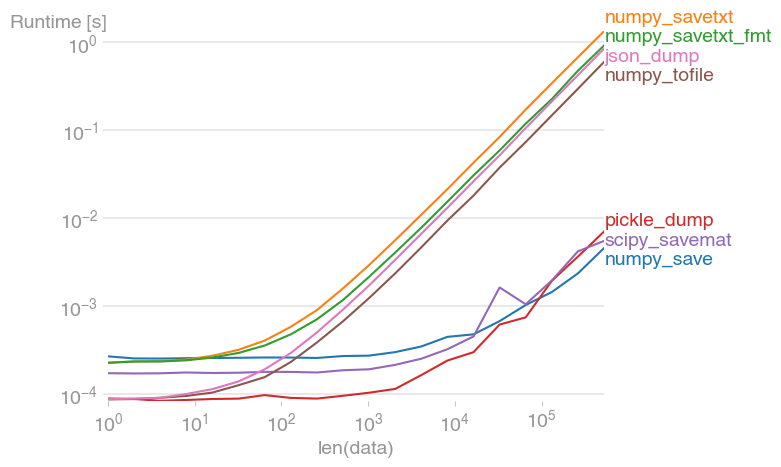
如果您希望将其写入磁盘,以便作为numpy数组轻松读取,请查看
numpy.save。pickle也可以正常工作,但对于大型数组效率较低(而您的数组不是很大,因此两种方法都可以)。
如果您希望它易于阅读,请查看
numpy.savetxt。
编辑:看起来
savetxt对于维数大于2的数组并不是很好......但只是为了将所有内容详细说明:
我刚意识到
numpy.savetxt会在ndarray中有超过2个维度时出错......这可能是设计上的问题,因为在文本文件中没有明确定义附加维度的方法。
例如:这个(2D数组)可以正常工作
import numpy as np
x = np.arange(20).reshape((4,5))
np.savetxt('test.txt', x)
当使用一个3D数组时,同样的操作将会失败(并且会返回一个不太详细的错误:TypeError: float argument required, not numpy.ndarray):
import numpy as np
x = np.arange(200).reshape((4,5,10))
np.savetxt('test.txt', x)
一种解决方法是将三维(或更高维)数组分成二维切片。例如:
x = np.arange(200).reshape((4,5,10))
with open('test.txt', 'w') as outfile:
for slice_2d in x:
np.savetxt(outfile, slice_2d)
然而,我们的目标是使内容易于人类阅读,并且仍然可以轻松地通过
numpy.loadtxt读取。因此,我们可以更加冗长,并使用注释行区分切片。默认情况下,
numpy.loadtxt将忽略任何以
#开头的行(或由
comments kwarg指定的任何字符)。 (这看起来比实际情况要冗长一些...)
import numpy as np
data = np.arange(200).reshape((4,5,10))
with open('test.txt', 'w') as outfile:
outfile.write('# Array shape: {0}\n'.format(data.shape))
for data_slice in data:
np.savetxt(outfile, data_slice, fmt='%-7.2f')
outfile.write('# New slice\n')
这将产生:
0.00 1.00 2.00 3.00 4.00 5.00 6.00 7.00 8.00 9.00
10.00 11.00 12.00 13.00 14.00 15.00 16.00 17.00 18.00 19.00
20.00 21.00 22.00 23.00 24.00 25.00 26.00 27.00 28.00 29.00
30.00 31.00 32.00 33.00 34.00 35.00 36.00 37.00 38.00 39.00
40.00 41.00 42.00 43.00 44.00 45.00 46.00 47.00 48.00 49.00
50.00 51.00 52.00 53.00 54.00 55.00 56.00 57.00 58.00 59.00
60.00 61.00 62.00 63.00 64.00 65.00 66.00 67.00 68.00 69.00
70.00 71.00 72.00 73.00 74.00 75.00 76.00 77.00 78.00 79.00
80.00 81.00 82.00 83.00 84.00 85.00 86.00 87.00 88.00 89.00
90.00 91.00 92.00 93.00 94.00 95.00 96.00 97.00 98.00 99.00
100.00 101.00 102.00 103.00 104.00 105.00 106.00 107.00 108.00 109.00
110.00 111.00 112.00 113.00 114.00 115.00 116.00 117.00 118.00 119.00
120.00 121.00 122.00 123.00 124.00 125.00 126.00 127.00 128.00 129.00
130.00 131.00 132.00 133.00 134.00 135.00 136.00 137.00 138.00 139.00
140.00 141.00 142.00 143.00 144.00 145.00 146.00 147.00 148.00 149.00
150.00 151.00 152.00 153.00 154.00 155.00 156.00 157.00 158.00 159.00
160.00 161.00 162.00 163.00 164.00 165.00 166.00 167.00 168.00 169.00
170.00 171.00 172.00 173.00 174.00 175.00 176.00 177.00 178.00 179.00
180.00 181.00 182.00 183.00 184.00 185.00 186.00 187.00 188.00 189.00
190.00 191.00 192.00 193.00 194.00 195.00 196.00 197.00 198.00 199.00
只要我们知道原始数组的形状,将其读回来非常容易。我们可以使用numpy.loadtxt('test.txt').reshape((4,5,10))。例如(你可以在一行中完成这个操作,我只是详细解释):
new_data = np.loadtxt('test.txt')
print new_data.shape
new_data = new_data.reshape((4,5,10))
assert np.all(new_data == data)
numpy.loadtxt(http://docs.scipy.org/doc/numpy/reference/generated/numpy.loadtxt.html)。 - Dominic Rodger