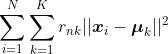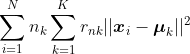我对k-means损失函数感到有些困惑。通常我找到的是这个损失函数: “with r_{nk} 表示观察值 x_i 是否属于聚类 k,\mu_k 表示聚类中心。然而在 Hastie、Tibshirani 和 Friedman 的书中,我发现:” “这样,具有更多观测值的聚类对于偏离聚类中心的反应更为敏感,其中n_k表示聚类k中的观测数。有人知道哪个是正确的吗?如果你有《统计学习基础》这本书,推导过程在第508-510页。”“干杯。”
实际上,正确的是您提到的第一个公式(非加权公式),书中第二个公式的推导是不正确的。该书用于推导其公式的主要方程式(14.3.6节中的方程式14.31)是不正确的,他们声称第一行和第二行之间存在相等关系。这里有一个小的反例,我们有1个簇(即K=1),和三个点(1,2,3)。 此外,在该书中,第510页的算法14.1是最小化您问题中的第一个损失函数的算法,而不是他们的损失函数。 我并没有说他们的最终公式没有意义,只是这个公式的推导对我来说似乎是错误的,并且他们展示的算法是已知最小化您的第一个函数的算法。请注意,在他们的算法中,权重N_k不存在,唯一确定一个点属于哪个簇的是该点与相关质心之间的距离,N_k与此无关,这表明该算法不是解决他们函数的工具。此外,如果我们有不平衡的聚类,即某些聚类比其他聚类具有更少的点数,它们使用N_k权重的公式促进切割大聚类的部分,并将它们分配给小邻居聚类,以避免拥有意味着更大损失的大N_k。