我正在尝试通过GridSearchCV找到最佳的xgboost模型,并且作为交叉验证,我想使用四月份的目标数据。以下是代码:
但是在我训练模型时出现了这个错误。 错误 请问有人能帮我解决这个问题吗?或者有人能建议我如何将未洗牌的数据拆分为训练/测试集,以便在最后一个月验证模型吗?
谢谢帮助。
x_train.head()
{kind=link}
{{链接1:x_train}}
。 y_train.head()
{kind=link}
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.metrics import make_scorer
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import TimeSeriesSplit
import xgboost as xg
xgb_parameters={'max_depth':[3,5,7,9],'min_child_weight':[1,3,5]}
xgb=xg.XGBRegressor(learning_rate=0.1, n_estimators=100,max_depth=5, min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8)
model=GridSearchCV(n_jobs=2,estimator=xgb,param_grid=xgb_parameters,cv=train_test_split(x_train,y_train,test_size=len(y_train['2016-04':'2016-04']), random_state=42, shuffle=False),scoring=my_func)
model.fit(x_train,y_train)
model.grid_scores_
model.best_params_
但是在我训练模型时出现了这个错误。 错误 请问有人能帮我解决这个问题吗?或者有人能建议我如何将未洗牌的数据拆分为训练/测试集,以便在最后一个月验证模型吗?
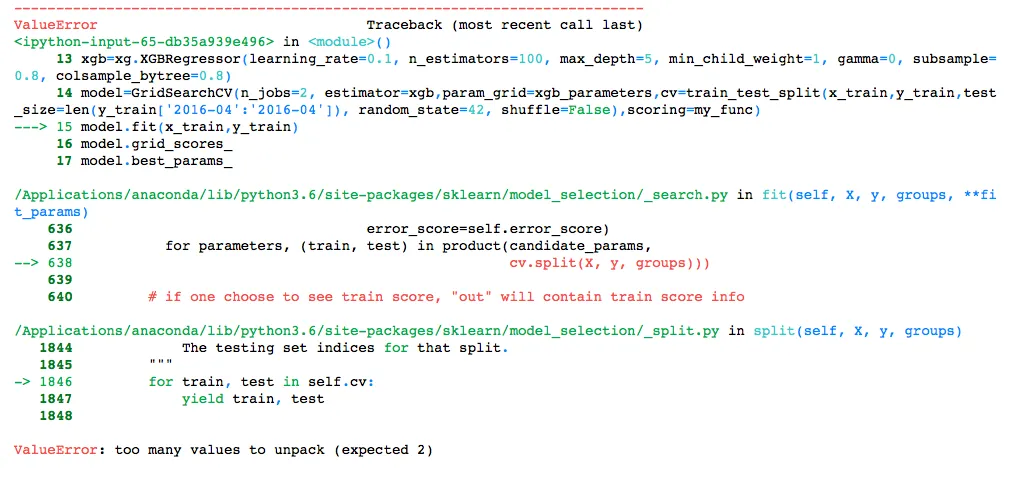{kind=link}
谢谢帮助。
test_size=len(y_train['2016-04':'2016-04'])- Ajay