我正在尝试使用Python中的正则表达式在多行搜索中查找并打印所有匹配行。我要搜索的文本可能具有以下示例结构:
问题是,尽管组捕获了我想要的内容:
以下是我用于解决这个问题的示例代码。
AAA ABC1 ABC2 ABC3 AAA ABC1 ABC2 ABC3 ABC4 ABC AAA ABC1 AAA我想从中检索至少出现一次且在AAA之前的ABC*s。
问题是,尽管组捕获了我想要的内容:
match = <_sre.SRE_Match object; span=(19, 38), match='AAA\nABC2\nABC3\nABC4\n'>
我只能访问到该组的最后一个匹配项:
match groups = ('AAA\n', 'ABC4\n')
以下是我用于解决这个问题的示例代码。
#! python
import sys
import re
import os
string = "AAA\nABC1\nABC2\nABC3\nAAA\nABC1\nABC2\nABC3\nABC4\nABC\nAAA\nABC1\nAAA\n"
print(string)
p_MATCHES = []
p_MATCHES.append( (re.compile('(AAA\n)(ABC[0-9]\n){1,}')) ) #
matches = re.finditer(p_MATCHES[0],string)
for match in matches:
strout = ''
gr_iter=0
print("match = "+str(match))
print("match groups = "+str(match.groups()))
for group in match.groups():
gr_iter+=1
sys.stdout.write("TEST GROUP:"+str(gr_iter)+"\t"+group) # test output
if group is not None:
if group != '':
strout+= '"'+group.replace("\n","",1)+'"'+'\n'
sys.stdout.write("\nCOMPLETE RESULT:\n"+strout+"====\n")
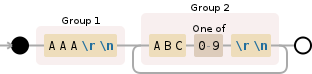
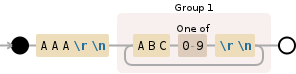
匹配分组 = ('AAA', 'ABC1', 'ABC2', 'ABC3', ...)我用这种解决方案得到的是匹配分组 = ('AAA', 'ABC1 \n ABC2 \n ABC3 \n')- glamredhel