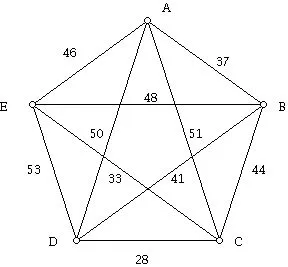
我有一个完整的加权图,每个权重代表下一个顶点属于相同类别的概率。我预先知道某些顶点所属的类别;那么我如何能够对其余每个顶点进行分类?
在你设置了所有这些规则和数字之后,一切都很琐碎 - 使用最小二乘高斯方法。至于迭代方式,要小心 - 你事先不知道解是否稳定或者是否存在。如果不是,迭代不会收敛,你为其编写的整个代码片段就毫无意义了。而通过高斯方法,你可以得到一组线性方程,并且标准算法被编写来解决所有情况。最后,你不仅拥有解决方案,还可以得到每个最终值的可能误差。
让w_i成为一个向量,其中w_i[j]是节点j在迭代i中属于簇的概率。
我们定义w_i:
w_0[j] = 1 j is given node in the class
0 otherwise
w_{i}[j] = P(j | w_{i-1})
其中:P(j | w_{i-1}) 是假设我们已知每个其他节点 k 在该聚类中的概率为 w_{i-1}[k] 的情况下,j 在该聚类中的概率。
我们可以计算上述概率:
P(j | w_{i-1}) = 1- (1- w_{i-1}[0]*c(0,j))*(1- w_{i-1}[1]*c(1,j))*...*(1- w_{i-1}[n-1]*c(n-1,j))
在这里:
w_{i-1} 是上一次迭代的输出。重复直到收敛,在收敛后的向量中(假设为 w),j 成为簇的概率为 w[j]。
概率函数的解释:
为了使一个节点不在集合中,需要所有其他节点“决定”不分享它。
因此,这种情况发生的概率是:
(1- w_{i-1}[0]*c(0,j))*(1- w_{i-1}[1]*c(1,j))*...*(1- w_{i-1}[n-1]*c(n-1,j))
^ ^ ^
node 0 doesn't share node 1 doesn't share node n-1 doesn't share
P(j | w_{i-1})公式。请保留HTML标签。