我正在使用Gensim Doc2Vec模型,尝试对客户支持对话的部分进行聚类。我的目标是为支持团队提供自动回复建议。
图1:显示了一个示例对话,在下一个对话线中回答用户问题,使得数据提取变得容易:
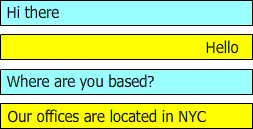
在对话期间,“hello”和“我们的办公室位于纽约”应该被建议
图2:描述了一个问题和答案不同步的对话
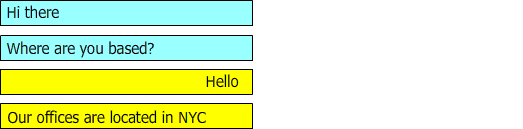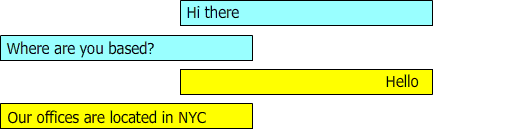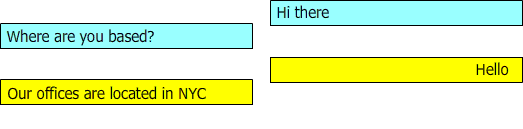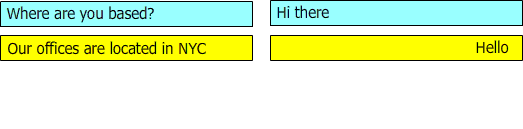
在对话期间,“hello”和“我们的办公室位于纽约”应该被建议
图3:描述了一个对话,其中答案的上下文逐渐建立,并且出于分类目的(我假设),某些行是冗余的。

在对话期间,应该建议“这是一个免费试用帐户的链接”
每个对话线的数据(简化)如下:
谁写了这行(用户还是代理),文本,时间戳
我正在使用以下代码来训练我的模型:
from gensim.models import Doc2Vec
from gensim.models.doc2vec import TaggedLineDocument
import datetime
print('Creating documents',datetime.datetime.now().time())
context = TaggedLineDocument('./test_data/context.csv')
print('Building model',datetime.datetime.now().time())
model = Doc2Vec(context,size = 200, window = 10, min_count = 10, workers=4)
print('Training...',datetime.datetime.now().time())
for epoch in range(10):
print('Run number :',epoch)
model.train(context)
model.save('./test_data/model')
问题: 我应该如何构建我的训练数据,有哪些启发式方法可以用来从原始数据中提取它?