我们有两个未排序的数组,每个数组的长度为n。这些数组包含在0-n100范围内的随机整数。如何在O(n)/线性时间内查找这两个数组是否具有任何公共元素?不允许排序。
8个回答
11
Hashtable 将会拯救你。真的,它就像算法中的瑞士军刀。
只需将第一个数组中的所有值放入其中,然后检查第二个数组中是否存在任何值。
- Nikita Rybak
16
2使用哈希表的时间复杂度为O(nlog n)。 - Neil
4@Neil:搜索通常是O(1),构建是O(n)。 (翻译成英文:@Neil: Searches are usually O(1), building is O(n).) - President James K. Polk
4虽然这是一种实践中不错的方法,但它不能达到O(n) 最坏情况 的性能。首先,因为哈希表在最坏情况下的查找是O(n)的(不良哈希函数,对于每个哈希函数,都存在具有许多哈希碰撞的输入),其次,您隐含地假设哈希函数可以在常数时间内计算,即使用于保存数字的位数不是恒定的。 - meriton
1@Neil,在提供的条件下,它是O(1)。有一个简单的证明:http://en.wikipedia.org/wiki/Hashtable#Performance_analysis 更不用说,哈希表与对数一般没有任何关系。 - Nikita Rybak
1@Nikita:每个条目最多为n^100,我认为可以使用100*log(n)的存储空间进行存储。因此,我猜测存储空间为O(n log n)。这是我对此问题的第三个答案,所以没有人应该相信它。 - President James K. Polk
显示剩余11条评论
6
您尚未定义计算模型。假设您只能在O(1)时间内读取O(1)位(否则将是一种相当奇特的计算模型),那么就不可能有能够以O(n)最坏情况时间复杂度解决问题的算法。
证明概述: 输入中的每个数字占用O(log(n ^ 100)) = O(100 log n) = O(log n) 位。因此,整个输入需要O(n log n)位,这在O(n)时间内无法读取。因此,任何O(n)算法都无法读取整个输入,因此也无法处理这些位是否重要。
证明概述: 输入中的每个数字占用O(log(n ^ 100)) = O(100 log n) = O(log n) 位。因此,整个输入需要O(n log n)位,这在O(n)时间内无法读取。因此,任何O(n)算法都无法读取整个输入,因此也无法处理这些位是否重要。
- meriton
10
1基数排序的时间复杂度为O(kn),其中n是数字的数量,k是数字的长度。如果k是常数,则为O(n),但在这里k是O(log n)。 - meriton
3这违背了问题的本意。此外,Word RAM模型并不那么奇特。事实上,大多数算法时间复杂度分析在未指定时都隐含使用它:O(1)时间数组访问,寄存器内两个适合整数的O(1)相加等。 - Aryabhatta
无论n的大小,“寄存器”和“字”都具有固定的大小。随着n的增加,这里的数字变得越来越长,使得无法将它们存储在恒定数量的“字”或“寄存器”中。 - meriton
这是在RAM计算模型中的错误答案,更多信息请参见此帖子:http://cs.stackexchange.com/questions/1643/how-can-we-assume-comparison-addition-between-numbers-is-o1 - Saeed Amiri
@SaeedAmiri:我不同意;事实上,我的“O(1)时间内的O(1)位”定义与链接问题的被接受答案所称的“计算的21世纪标准模型:整数RAM”是一致的。然而,该问题将
n定义为输入数组的“长度”,而不是它占用的内存单元数。你不能用n个内存单元存储100 log n位数字的2n个数字。 - meriton显示剩余5条评论
2
线性测试
使用Mathematica哈希函数和任意长度整数。
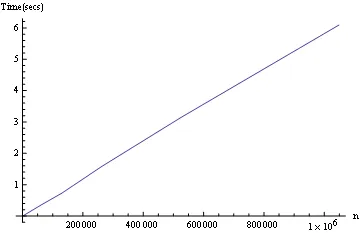
测试直到 n=2^20,生成随机数直到(2^20)^100 = (约10^602)。
为了防止误解...程序如下:
k = {};
For[t = 1, t < 21, t++,
i = 2^t;
Clear[a, b];
Table[a[RandomInteger[i^100]] = 1, {i}];
b = Table[RandomInteger[i^100], {i}];
Contains = False;
AppendTo[k,
{i, First@Timing@For[j = 2, j <= i, j++,
Contains = Contains || (NumericQ[a[b[[j]]]]);
]}]];
ListLinePlot[k, PlotRange -> All, AxesLabel -> {"n", "Time(secs)"}]
- Dr. belisarius
4
呵呵,一个人拿着一张图表出现,整个房间都安静了下来。我们知道哈希表的平均情况性能是线性的。 - President James K. Polk
1@GregS 这个案例是针对任意长度整数的。我们都知道哈希部分。 - Dr. belisarius
评估
a[b[j]] 需要 O(log n) 步骤,因为 b[j] 包含 O(log n) 位数字。平均而言,b 中的第一个重复项出现在位置 n/2。实际上,在您的示例中,列表之间可能没有重复项,因此在失败之前必须遍历整个列表。无论图表显示什么,对我来说都像是 O(n log n)。 - President James K. Polk@GregS 这就是我首先制作图形的原因。我的赌注并不是线性的。也许我们可以进行另一项测试来展示你的洞察力? - Dr. belisarius
2
回答Neil:
由于您在开始时知道什么是您的N(大小为N的两个数组),因此您可以创建一个哈希表,其数组大小为2 * N *某些比率(例如:some_ratio = 1.5)。使用此大小,几乎所有简单的哈希函数都会为您提供良好的实体分布。
您还可以实现“查找或插入”以在同一操作中搜索现有项或插入新项,这将减少哈希函数和比较调用。(c++ stl find_or_insert不够好,因为它不能告诉您该项以前是否存在)。
您还可以实现“查找或插入”以在同一操作中搜索现有项或插入新项,这将减少哈希函数和比较调用。(c++ stl find_or_insert不够好,因为它不能告诉您该项以前是否存在)。
- Guy Nir
2
1他说存储不是问题。Hashtable 是存储和访问速度之间的折衷方案。如果我不必妥协存储,为什么要这样做呢? - Neil
如果数值范围可以适应 RAM 内存,那么您的方法是好的,但是32位的范围是4GB,即使今天来看也被认为是非常大的范围。(由于需要额外的内存,4GB Ram 是不够用的,因此并非每台计算机都能在 RAM 上运行)。如果您采用 64 位范围,毫无疑问您永远无法获得足够的内存。 - Guy Nir
1
如果存储不重要,那么可以放弃使用哈希表,而采用长度为n的数组。在第一次遍历数组时,当你找到该数字时将标记设置为true。在遍历第二个数组时,如果发现任何一个标记为true,则已经得到了答案。时间复杂度为O(n)。
Define largeArray(n)
// First pass
for(element i in firstArray)
largeArray[i] = true;
// Second pass
Define hasFound = false;
for(element i in secondArray)
if(largeArray[i] == true)
hasFound = true;
break;
- Neil
12
我的意思是,如果你执行array[currentNumber]并且它为true,那么这意味着相同的数字存在于第一个数组中,因此你已经找到了解决方案。你不需要搜索数组中的所有值,因为索引本身就是你要查找的数字。 - Neil
输入中的数字可以达到n^100这么大。因此,你的数组必须能够容纳n^100个元素。我向你提出挑战,在O(n)的时间内初始化该数组。 - meriton
对于大数组中的每个元素e,e=false。只要我进行的遍历次数是恒定的,它总是O(n)。 - Neil
1按照这个逻辑,所有的算法都是O(n),你只需要使用正确的n定义。你忽略了n代表输入长度这一点。你不能选择它,因为输入决定了它。如果你不相信我,我建议你阅读一下O-Notation;这显然超出了这个问题的范围。 - meriton
1@Neil:关键在于你的数组大小是O(n log n),而不是O(n)。因此,初始化你的数组需要O(n log n)的时间。 - President James K. Polk
显示剩余7条评论
1
将第一个数组的元素放入哈希表中,并扫描第二个数组以检查其是否存在。这样可以在平均情况下得到O(N)的解决方案。
如果您想要真正的O(N)最坏情况解决方案,那么请使用线性数组,范围为0-n^100,而不是使用哈希表。请注意,您只需要使用每个条目的单个位。
如果您想要真正的O(N)最坏情况解决方案,那么请使用线性数组,范围为0-n^100,而不是使用哈希表。请注意,您只需要使用每个条目的单个位。
- antirez
8
不是错误,但仅初始化数组就需要O(n log n)的时间复杂度。 - President James K. Polk
你如何在O(n)时间内初始化大小为O(n^100)的数组?你的算法假设数组中的所有位最初都是0。 - meriton
@GregS:在我们的理论模型中,内存访问应该是O(1),堆分配也是如此:均摊时间为O(1)。因此,使用全零初始化数组只需要O(N)的时间。 - antirez
这个问题没有定义计算模型。然而,一个允许在O(1)时间内写入O(log n)位的计算模型对我来说似乎很奇怪。如果我的输入变大,内存会变快吗...? - meriton
对不起,我完全专注于O(N)个不同元素的想法,而不是n^100个元素。很抱歉误读了原问题。顺便说一句,这个问题很奇怪,因为没有办法将其转化为O(N),因为这实际上需要一种非常奇怪的内存模型,在其中我们可以在O(log n)时间内分配清零位。 - antirez
显示剩余3条评论
0
根据迄今为止发布的想法,我们可以将一个数组整数元素存储到哈希映射中。RAM中可以存储最大数量的不同整数。哈希映射将仅具有唯一的整数值。重复项将被忽略。
以下是Perl语言的实现。
以下是Perl语言的实现。
#!/usr/bin/perl
use strict;
use warnings;
sub find_common_elements{ # function that prints common elements in two unsorted array
my (@arr1,@array2)=@_; # array elements assumed to be filled and passed as function arguments
my $hash; # hash map to store value of one array
# runtime to prepare hash map is O(n).
foreach my $ele ($arr1){
$hash->{$ele}=true; # true here element exists key is integer number and value is true, duplicate elements will be overwritten
# size of array will fit in memory as duplicate integers are ignored ( mx size will be 2 ^( 32) -1 or 2^(64) -1 based on operating system) which can be stored in RAM.
}
# O(n ) to traverse second array and finding common elements in two array
foreach my $ele2($arr2){
# search in hash map is O(1), if all integers of array are same then hash map will have only one entry and still search tim is O(1)
if( defined $hash->{$ele}){
print "\n $ele is common in both array \n";
}
}
}
希望它有所帮助。
- Giridhar
0
你尝试过计数排序吗?它实现简单,使用O(n)空间,并且具有\theta(n)时间复杂度。
- David Weiser
2
...对于长度不取决于输入大小的数字,这种算法是有效的。但是,在这里,随着输入变得更长,数字也变得越来越大... - meriton
问题陈述为“这些数组包含范围在0-n100之间的随机整数。”因此,我们知道数字的分布情况,因此计数排序是一种选择。如果数字很稀疏,那么这种排序将浪费大量空间,你说得对。我只是提出了一个其他人尚未提出的想法。 - David Weiser
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 3 两个O(n^2)算法的时间复杂度相同吗?
- 3 修改后的快速排序算法能够在最优情况下达到O(n)的时间复杂度吗?
- 8 算法分析 - 在排序数组中查找缺失的整数,时间复杂度优于O(n)
- 3 在O(lg n)的时间复杂度内,在已排序的数组中查找主要元素
- 3 O(n)时间复杂度的算法是否总是比O(n^2)时间复杂度的算法更快?
- 8 具有O(n * log(n))时间复杂度和O(1)空间复杂度的稳定排序算法比较。
- 5 这个排序算法的时间复杂度(Big O)。
- 5 搜索算法的时间复杂度为O(log n),未排序的列表/数组
- 65 在时间复杂度为O(n)的情况下查找数组中的重复元素
- 4 在未排序的行中,以O(n)时间复杂度在二维数组中搜索。