我希望能够根据一列对行进行分组排序(在我的示例中,“Group”是要分组并按顺序排序的列)。我无法按索引排序,因为索引由于先前的操作而有意被打乱了顺序。
如果有帮助的话,原始的
df = pd.DataFrame({
'Group':[5,5,5,9,9,777,777,1,2,2],
'V1':['a','b','a',3,6,1,None,10,3,None],
'V2':['blah','blah','blah','dog','cat','cat','na','first','last','nada'],
'V3':[1,2,3,4,5,5,4,3,2,1,]
})
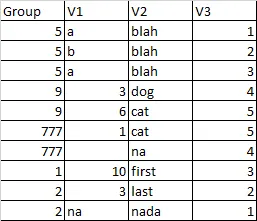
并希望它看起来像这样:
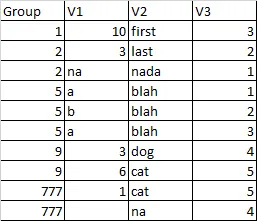
我已经尝试了各种方法,比如
df.groupby(['Group'])['Group']).aggregate({'min grp':'min'}).sort_values(by=['min grp'], ascending=True)
如果有帮助的话,原始的
df 是通过 pd.concat(list-of-dataframes) 创建的,当我之后按照 Group 对它们进行排序时,它也会根据索引对 Group 内的行进行排序,这对于我的特定问题不起作用。