我能从已训练的决策树中提取出底层的决策规则(或“决策路径”),并将其以文本列表形式呈现吗?
类似这样:
if A>0.4 then if B<0.2 then if C>0.8 then class='X'
我能从已训练的决策树中提取出底层的决策规则(或“决策路径”),并将其以文本列表形式呈现吗?
类似这样:
if A>0.4 then if B<0.2 then if C>0.8 then class='X'
我认为这个答案比其他答案更正确:
from sklearn.tree import _tree
def tree_to_code(tree, feature_names):
tree_ = tree.tree_
feature_name = [
feature_names[i] if i != _tree.TREE_UNDEFINED else "undefined!"
for i in tree_.feature
]
print "def tree({}):".format(", ".join(feature_names))
def recurse(node, depth):
indent = " " * depth
if tree_.feature[node] != _tree.TREE_UNDEFINED:
name = feature_name[node]
threshold = tree_.threshold[node]
print "{}if {} <= {}:".format(indent, name, threshold)
recurse(tree_.children_left[node], depth + 1)
print "{}else: # if {} > {}".format(indent, name, threshold)
recurse(tree_.children_right[node], depth + 1)
else:
print "{}return {}".format(indent, tree_.value[node])
recurse(0, 1)
这会打印出一个有效的Python函数。以下是一棵试图返回其输入(介于0到10之间的数字)的树的示例输出。
def tree(f0):
if f0 <= 6.0:
if f0 <= 1.5:
return [[ 0.]]
else: # if f0 > 1.5
if f0 <= 4.5:
if f0 <= 3.5:
return [[ 3.]]
else: # if f0 > 3.5
return [[ 4.]]
else: # if f0 > 4.5
return [[ 5.]]
else: # if f0 > 6.0
if f0 <= 8.5:
if f0 <= 7.5:
return [[ 7.]]
else: # if f0 > 7.5
return [[ 8.]]
else: # if f0 > 8.5
return [[ 9.]]
以下是其他回答中存在的一些问题:
tree_.threshold == -2 判断一个节点是否为叶子节点不是一个好主意。如果它是一个具有阈值为-2的真正决策节点怎么办?相反,您应该查看 tree.feature 或 tree.children_*。features = [feature_names[i] for i in tree_.feature] 会导致我的 sklearn 版本崩溃,因为一些 tree.tree_.feature 的值为-2(特别是对于叶子节点)。print "{}return {}".format(indent, tree_.value[node])更改为print "{}return {}".format(indent, np.argmax(tree_.value[node][0])),以便函数返回类索引。 - soupaultRandomForestClassifier.estimators_,但我无法想出如何组合估算器的结果。 - Nathan Lloydprint "bla" => print("bla") - Nir我创建了自己的函数,从sklearn创建的决策树中提取规则:
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
# dummy data:
df = pd.DataFrame({'col1':[0,1,2,3],'col2':[3,4,5,6],'dv':[0,1,0,1]})
# create decision tree
dt = DecisionTreeClassifier(max_depth=5, min_samples_leaf=1)
dt.fit(df.ix[:,:2], df.dv)
这个函数首先从节点开始(由子数组中的-1标识),然后递归地查找父节点。我称之为节点的“血统”。在此过程中,我获取了创建if/then/else SAS逻辑所需的值:
def get_lineage(tree, feature_names):
left = tree.tree_.children_left
right = tree.tree_.children_right
threshold = tree.tree_.threshold
features = [feature_names[i] for i in tree.tree_.feature]
# get ids of child nodes
idx = np.argwhere(left == -1)[:,0]
def recurse(left, right, child, lineage=None):
if lineage is None:
lineage = [child]
if child in left:
parent = np.where(left == child)[0].item()
split = 'l'
else:
parent = np.where(right == child)[0].item()
split = 'r'
lineage.append((parent, split, threshold[parent], features[parent]))
if parent == 0:
lineage.reverse()
return lineage
else:
return recurse(left, right, parent, lineage)
for child in idx:
for node in recurse(left, right, child):
print node
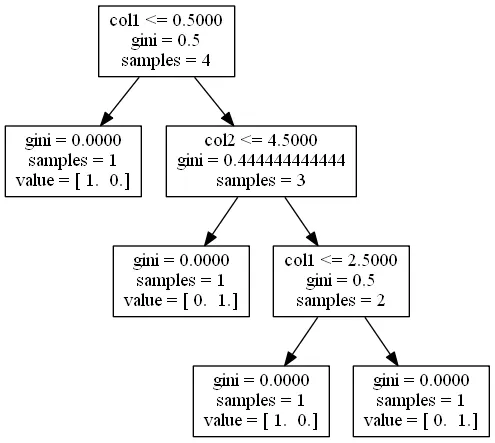
do代码块,这就是为什么我会描述一个节点整个路径的逻辑。元组后面的单个整数是路径中终端节点的ID。所有前面的元组组合起来创建了那个节点。In [1]: get_lineage(dt, df.columns)
(0, 'l', 0.5, 'col1')
1
(0, 'r', 0.5, 'col1')
(2, 'l', 4.5, 'col2')
3
(0, 'r', 0.5, 'col1')
(2, 'r', 4.5, 'col2')
(4, 'l', 2.5, 'col1')
5
(0, 'r', 0.5, 'col1')
(2, 'r', 4.5, 'col2')
(4, 'r', 2.5, 'col1')
6
Scikit learn在2019年5月的0.21版本中引入了一种美味的新方法,称为export_text,用于从树中提取规则。这里是文档链接。现在不再需要创建自定义函数。
一旦您拟合了模型,您只需要两行代码。首先导入export_text:
from sklearn.tree import export_text
其次, 创建一个包含规则的对象。为了使规则更易读,使用feature_names参数并传递一个特征名列表。例如,如果您的模型名称为model,并且您的特征以数据帧X_train的形式命名,您可以创建一个名为tree_rules的对象:
tree_rules = export_text(model, feature_names=list(X_train.columns))
然后只需打印或保存tree_rules。您的输出将如下所示:
|--- Age <= 0.63
| |--- EstimatedSalary <= 0.61
| | |--- Age <= -0.16
| | | |--- class: 0
| | |--- Age > -0.16
| | | |--- EstimatedSalary <= -0.06
| | | | |--- class: 0
| | | |--- EstimatedSalary > -0.06
| | | | |--- EstimatedSalary <= 0.40
| | | | | |--- EstimatedSalary <= 0.03
| | | | | | |--- class: 1
我修改了由Zelazny7提交的代码来打印一些伪代码:
def get_code(tree, feature_names):
left = tree.tree_.children_left
right = tree.tree_.children_right
threshold = tree.tree_.threshold
features = [feature_names[i] for i in tree.tree_.feature]
value = tree.tree_.value
def recurse(left, right, threshold, features, node):
if (threshold[node] != -2):
print "if ( " + features[node] + " <= " + str(threshold[node]) + " ) {"
if left[node] != -1:
recurse (left, right, threshold, features,left[node])
print "} else {"
if right[node] != -1:
recurse (left, right, threshold, features,right[node])
print "}"
else:
print "return " + str(value[node])
recurse(left, right, threshold, features, 0)
如果您在相同的示例上调用get_code(dt, df.columns),您将获得:
if ( col1 <= 0.5 ) {
return [[ 1. 0.]]
} else {
if ( col2 <= 4.5 ) {
return [[ 0. 1.]]
} else {
if ( col1 <= 2.5 ) {
return [[ 1. 0.]]
} else {
return [[ 0. 1.]]
}
}
}
(threshold[node] != -2)更改为(left[node] != -1)(类似于下面获取子节点ID的方法)。 - tlingf在 0.18.0 版本中,有一个新的 DecisionTreeClassifier 方法 decision_path。开发人员提供了一份详细(有文档说明)演示文稿。
演示文稿中打印树结构的第一部分代码似乎没问题。然而,我修改了第二部分代码来查询一个样本。我的更改用 # <-- 标记出来。
编辑: 在 #8653 和 #10951 的推送请求指出错误后,下面代码中用 # <-- 标记的更改已在演示文稿链接中得到更新。现在更容易跟随了。
sample_id = 0
node_index = node_indicator.indices[node_indicator.indptr[sample_id]:
node_indicator.indptr[sample_id + 1]]
print('Rules used to predict sample %s: ' % sample_id)
for node_id in node_index:
if leave_id[sample_id] == node_id: # <-- changed != to ==
#continue # <-- comment out
print("leaf node {} reached, no decision here".format(leave_id[sample_id])) # <--
else: # < -- added else to iterate through decision nodes
if (X_test[sample_id, feature[node_id]] <= threshold[node_id]):
threshold_sign = "<="
else:
threshold_sign = ">"
print("decision id node %s : (X[%s, %s] (= %s) %s %s)"
% (node_id,
sample_id,
feature[node_id],
X_test[sample_id, feature[node_id]], # <-- changed i to sample_id
threshold_sign,
threshold[node_id]))
Rules used to predict sample 0:
decision id node 0 : (X[0, 3] (= 2.4) > 0.800000011921)
decision id node 2 : (X[0, 2] (= 5.1) > 4.94999980927)
leaf node 4 reached, no decision here
from StringIO import StringIO
out = StringIO()
out = tree.export_graphviz(clf, out_file=out)
print out.getvalue()
您可以看到一个有向图树。然后,clf.tree_.feature 和 clf.tree_.value 分别是节点拆分特征和节点值的数组。您可以从这个github源代码中了解更多细节。
我需要一种更人性化的决策树规则格式。我正在构建开源AutoML Python包,许多MLJAR用户想要查看树中的确切规则。
这就是为什么我基于paulkernfeld的回答实现了一个函数。
def get_rules(tree, feature_names, class_names):
tree_ = tree.tree_
feature_name = [
feature_names[i] if i != _tree.TREE_UNDEFINED else "undefined!"
for i in tree_.feature
]
paths = []
path = []
def recurse(node, path, paths):
if tree_.feature[node] != _tree.TREE_UNDEFINED:
name = feature_name[node]
threshold = tree_.threshold[node]
p1, p2 = list(path), list(path)
p1 += [f"({name} <= {np.round(threshold, 3)})"]
recurse(tree_.children_left[node], p1, paths)
p2 += [f"({name} > {np.round(threshold, 3)})"]
recurse(tree_.children_right[node], p2, paths)
else:
path += [(tree_.value[node], tree_.n_node_samples[node])]
paths += [path]
recurse(0, path, paths)
# sort by samples count
samples_count = [p[-1][1] for p in paths]
ii = list(np.argsort(samples_count))
paths = [paths[i] for i in reversed(ii)]
rules = []
for path in paths:
rule = "if "
for p in path[:-1]:
if rule != "if ":
rule += " and "
rule += str(p)
rule += " then "
if class_names is None:
rule += "response: "+str(np.round(path[-1][0][0][0],3))
else:
classes = path[-1][0][0]
l = np.argmax(classes)
rule += f"class: {class_names[l]} (proba: {np.round(100.0*classes[l]/np.sum(classes),2)}%)"
rule += f" | based on {path[-1][1]:,} samples"
rules += [rule]
return rules
规则按照每个规则分配的训练样本数量进行排序。对于每个规则,都有关于分类任务预测类名和预测概率的信息。对于回归任务,只打印有关预测值的信息。
from sklearn import datasets
from sklearn.tree import DecisionTreeRegressor
from sklearn import tree
from sklearn.tree import _tree
# Prepare the data data
boston = datasets.load_boston()
X = boston.data
y = boston.target
# Fit the regressor, set max_depth = 3
regr = DecisionTreeRegressor(max_depth=3, random_state=1234)
model = regr.fit(X, y)
# Print rules
rules = get_rules(regr, boston.feature_names, None)
for r in rules:
print(r)
印刷的规则:
if (RM <= 6.941) and (LSTAT <= 14.4) and (DIS > 1.385) then response: 22.905 | based on 250 samples
if (RM <= 6.941) and (LSTAT > 14.4) and (CRIM <= 6.992) then response: 17.138 | based on 101 samples
if (RM <= 6.941) and (LSTAT > 14.4) and (CRIM > 6.992) then response: 11.978 | based on 74 samples
if (RM > 6.941) and (RM <= 7.437) and (NOX <= 0.659) then response: 33.349 | based on 43 samples
if (RM > 6.941) and (RM > 7.437) and (PTRATIO <= 19.65) then response: 45.897 | based on 29 samples
if (RM <= 6.941) and (LSTAT <= 14.4) and (DIS <= 1.385) then response: 45.58 | based on 5 samples
if (RM > 6.941) and (RM <= 7.437) and (NOX > 0.659) then response: 14.4 | based on 3 samples
if (RM > 6.941) and (RM > 7.437) and (PTRATIO > 19.65) then response: 21.9 | based on 1 samples
from sklearn.tree import _tree - JP Zhang现在您可以使用export_text功能。
from sklearn.tree import export_text
r = export_text(loan_tree, feature_names=(list(X_train.columns)))
print(r)
这是一个来自[sklearn][1]的完整示例:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_text
iris = load_iris()
X = iris['data']
y = iris['target']
decision_tree = DecisionTreeClassifier(random_state=0, max_depth=2)
decision_tree = decision_tree.fit(X, y)
r = export_text(decision_tree, feature_names=iris['feature_names'])
print(r)
这是你所需要的代码
我已经修改了最受欢迎的代码,以正确地在Jupyter Notebook Python 3中缩进
import numpy as np
from sklearn.tree import _tree
def tree_to_code(tree, feature_names):
tree_ = tree.tree_
feature_name = [feature_names[i]
if i != _tree.TREE_UNDEFINED else "undefined!"
for i in tree_.feature]
print("def tree({}):".format(", ".join(feature_names)))
def recurse(node, depth):
indent = " " * depth
if tree_.feature[node] != _tree.TREE_UNDEFINED:
name = feature_name[node]
threshold = tree_.threshold[node]
print("{}if {} <= {}:".format(indent, name, threshold))
recurse(tree_.children_left[node], depth + 1)
print("{}else: # if {} > {}".format(indent, name, threshold))
recurse(tree_.children_right[node], depth + 1)
else:
print("{}return {}".format(indent, np.argmax(tree_.value[node])))
recurse(0, 1)
if A>0.4 then if B<0.2 then if C>0.8 then class='X'
我采用了@paulkernfeld的答案(感谢),你可以根据自己的需要进行个性化设置。
def tree_to_code(tree, feature_names, Y):
tree_ = tree.tree_
feature_name = [
feature_names[i] if i != _tree.TREE_UNDEFINED else "undefined!"
for i in tree_.feature
]
pathto=dict()
global k
k = 0
def recurse(node, depth, parent):
global k
indent = " " * depth
if tree_.feature[node] != _tree.TREE_UNDEFINED:
name = feature_name[node]
threshold = tree_.threshold[node]
s= "{} <= {} ".format( name, threshold, node )
if node == 0:
pathto[node]=s
else:
pathto[node]=pathto[parent]+' & ' +s
recurse(tree_.children_left[node], depth + 1, node)
s="{} > {}".format( name, threshold)
if node == 0:
pathto[node]=s
else:
pathto[node]=pathto[parent]+' & ' +s
recurse(tree_.children_right[node], depth + 1, node)
else:
k=k+1
print(k,')',pathto[parent], tree_.value[node])
recurse(0, 1, 0)