我正在使用Python的XGBoost,并成功地使用XGBoost的train()函数训练了一个模型,该函数针对DMatrix数据进行调用。该矩阵是从Pandas数据框中创建的,该数据框具有列的特征名称。
Xtrain, Xval, ytrain, yval = train_test_split(df[feature_names], y, \
test_size=0.2, random_state=42)
dtrain = xgb.DMatrix(Xtrain, label=ytrain)
model = xgb.train(xgb_params, dtrain, num_boost_round=60, \
early_stopping_rounds=50, maximize=False, verbose_eval=10)
fig, ax = plt.subplots(1,1,figsize=(10,10))
xgb.plot_importance(model, max_num_features=5, ax=ax)
我现在想使用xgboost.plot_importance()函数查看特征重要性,但结果图中没有显示特征名称。相反,特征被列为f1、f2、f3等,如下所示。
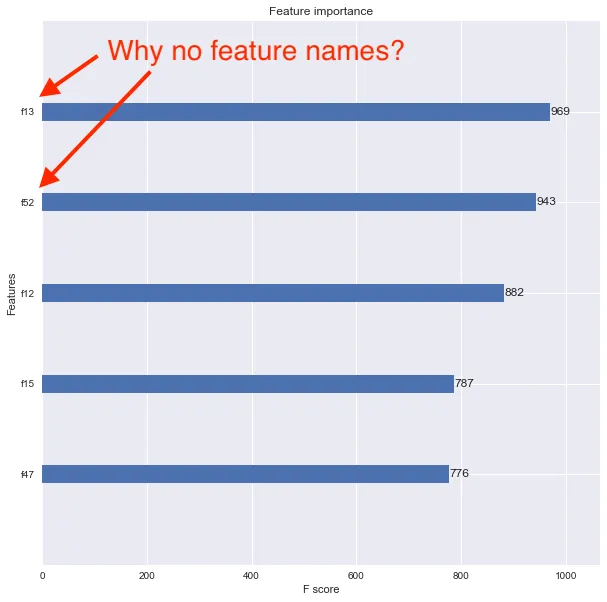
我认为问题在于我将原始的Pandas数据框转换为DMatrix。如何适当地关联特征名称,以便特征重要性图表显示它们?
f##功能名称上? - undefined