假设我们有以下情况:
- 有一枚硬币,如果正面朝上,则下一次翻转为正面的概率为0.6(反面朝上则下一次翻转为反面的概率也为0.6) - 一个班级里有100名学生 - 每个学生随机翻转这枚硬币多次 - 第n个学生的最后一次翻转不会影响第n+1个学生的第一次翻转(即当下一个学生翻转硬币时,第一次翻转正反面的概率为0.5,但该学生的下一次翻转取决于前一次翻转结果)
以下是用R代码表示这个问题的方式:
- 有一枚硬币,如果正面朝上,则下一次翻转为正面的概率为0.6(反面朝上则下一次翻转为反面的概率也为0.6) - 一个班级里有100名学生 - 每个学生随机翻转这枚硬币多次 - 第n个学生的最后一次翻转不会影响第n+1个学生的第一次翻转(即当下一个学生翻转硬币时,第一次翻转正反面的概率为0.5,但该学生的下一次翻转取决于前一次翻转结果)
以下是用R代码表示这个问题的方式:
library(tidyverse)
set.seed(123)
ids <- 1:100
student_id <- sort(sample(ids, 100000, replace = TRUE))
coin_result <- character(1000)
coin_result[1] <- sample(c("H", "T"), 1)
for (i in 2:length(coin_result)) {
if (student_id[i] != student_id[i-1]) {
coin_result[i] <- sample(c("H", "T"), 1)
} else if (coin_result[i-1] == "H") {
coin_result[i] <- sample(c("H", "T"), 1, prob = c(0.6, 0.4))
} else {
coin_result[i] <- sample(c("H", "T"), 1, prob = c(0.4, 0.6))
}
}
my_data <- data.frame(student_id, coin_result)
my_data <- my_data[order(my_data$student_id),]
final <- my_data %>%
group_by(student_id) %>%
mutate(flip_number = row_number())
The data looks something like this:
# A tibble: 6 x 3
# Groups: student_id [1]
student_id coin_result flip_number
<int> <chr> <int>
1 1 H 1
2 1 H 2
3 1 H 3
4 1 H 4
5 1 T 5
6 1 H 6
我的问题:在这种情况下,假设我对这个硬币没有任何先前的了解(即我只能访问学生提供的数据),我认为这个硬币可能具有“相关概率” - 特别是,我认为上一次抛硬币的结果可能会影响下一次抛硬币的结果。为了测试这个假设,我可以进行以下分析:
随机有放回地从学生中抽样,直到你获得与原始数据相同数量的学生。
对于每个被选中的学生,随机选择一个起点x和终点y(其中y > x),并选择给定学生在x和y之间的所有可用数据。
然后,计算概率和95%置信区间。
重复这个过程k次。
以下是我编写上述过程的代码尝试:
library(dplyr)
set.seed(123)
n_boot <- 1000
boot_results2 <- matrix(NA, nrow = n_boot, ncol = 4)
colnames(boot_results2) <- c("P(H|H)", "P(T|H)", "P(H|T)", "P(T|T)")
for (b in 1:n_boot) {
print(b)
boot_students <- sample(unique(final$student_id), replace = TRUE)
boot_data <- data.frame(student_id = integer(0), coin_result = character(0), stringsAsFactors = FALSE)
for (s in boot_students) {
student_data <- final %>% filter(student_id == s)
x <- sample(nrow(student_data), 1)
y <- sample(x:nrow(student_data), 1)
student_data <- student_data[x:y, ]
boot_data <- rbind(boot_data, student_data)
}
p_hh <- mean(boot_data$coin_result[-1] == "H" & boot_data$coin_result[-nrow(boot_data)] == "H")
p_th <- mean(boot_data$coin_result[-1] == "H" & boot_data$coin_result[-nrow(boot_data)] == "T")
p_ht <- mean(boot_data$coin_result[-1] == "T" & boot_data$coin_result[-nrow(boot_data)] == "H")
p_tt <- mean(boot_data$coin_result[-1] == "T" & boot_data$coin_result[-nrow(boot_data)] == "T")
boot_results2[b, ] <- c(p_hh, p_th, p_ht, p_tt)
}
我的问题:虽然代码似乎在运行,但运行时间很长。我也不确定我是否写对了。
有人可以请指导我如何正确地做吗?
谢谢!
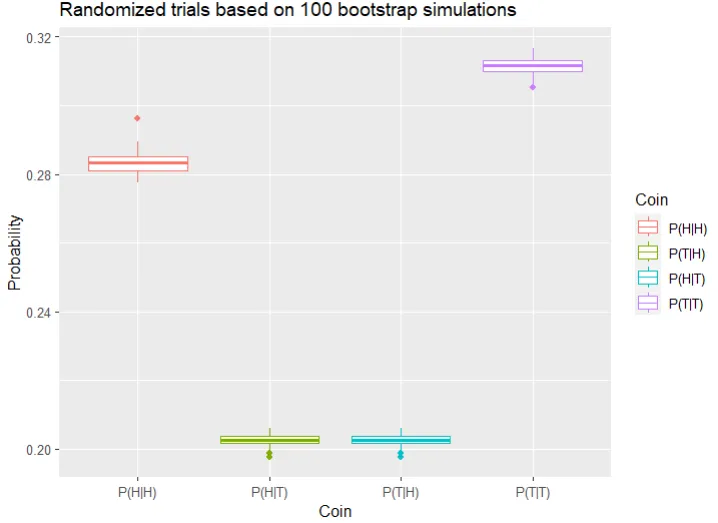
注:可选的代码用于可视化结果:
library(ggplot2)
boot_results_long2 <- as.data.frame(boot_results2)
boot_results_long2$iteration <- 1:n_boot
boot_results_long2 <- boot_results_long2 %>%
gather(key = "coin", value = "probability", -iteration)
ggplot(boot_results_long2, aes(x = iteration, y = probability, color = coin)) +
geom_line() +
labs(x = "Iteration", y = "Probability", color = "Coin") +
scale_color_discrete(labels = c("P(H|H)", "P(T|H)", "P(H|T)", "P(T|T)"))
- 它运行缓慢的原因很可能是你在使用for循环(而且可能还有嵌套的for循环)。如果你能将代码改写成使用
- Markmap或apply,那么速度可能会稍微提升一些。你可以在这里或者Code Review上获取更多建议,我不确定。- 它运行缓慢的原因很可能是你在使用for循环(而且可能还有嵌套的for循环)。如果你能将代码改写成使用
- undefinedmap或apply,那么速度可能会有所提升。你可以在这里或者在代码审查网站上获取更多建议,我不确定。