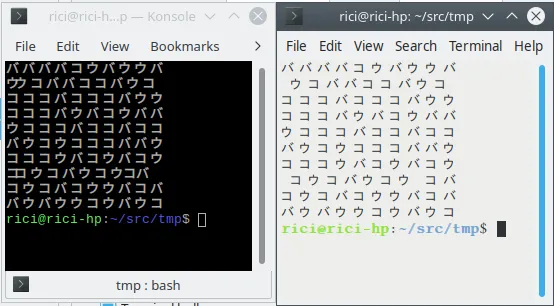
在下面的程序中,我尝试使用ncurses输出十行每行十个Unicode字符。循环的每次迭代会从三个Unicode字符的数组中选择一个随机字符。然而,我遇到的问题是ncurses不总是会每行写入十个字符...这有点难以解释,但如果您运行该程序,也许您会看到这里和那里有空格。有些行将包含十个字符,有些只有九个,有些只有八个。此时,我不知道自己在做错了什么。
我在Ubuntu20.04.1计算机上运行此程序,并使用默认GUI终端。
我在Ubuntu20.04.1计算机上运行此程序,并使用默认GUI终端。
#define _XOPEN_SOURCE_EXTENDED 1
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <ncurses.h>
#include <locale.h>
#include <time.h>
#define ITERATIONS 3000
#define REFRESH_DELAY 720000L
#define MAXX 10
#define MAXY 10
#define RANDOM_KANA &katakana[(rand()%3)]
#define SAME_KANA &katakana[2]
void show();
cchar_t katakana[3];
cchar_t kana1;
cchar_t kana2;
cchar_t kana3;
int main() {
setlocale(LC_ALL, "");
srand(time(0));
setcchar(&kana1, L"\u30d0", WA_NORMAL, 5, NULL);
setcchar(&kana2, L"\u30a6", WA_NORMAL, 4, NULL);
setcchar(&kana3, L"\u30b3", WA_NORMAL, 4, NULL);
katakana[0] = kana1;
katakana[1] = kana2;
katakana[2] = kana3;
initscr();
for (int i=0; i < ITERATIONS; i++) {
show();
usleep(REFRESH_DELAY);
}
}
void show() {
for (int x=0; x < MAXX; x++) {
for (int y = 0; y < MAXY; y++) {
mvadd_wch(y, x, RANDOM_KANA);
}
}
refresh();
//getch();
}