我想要使用groupby.agg函数,其中我的分组是整个数据框。 换句话说,我想使用agg功能,但不需要进行分组。我已经寻找了这方面的示例,但没有找到。
以下是我的操作:
import pandas as pd
import numpy as np
np.random.seed([3,1415])
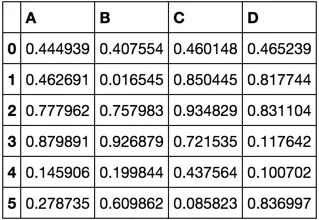
df = pd.DataFrame(np.random.rand(6, 4), columns=list('ABCD'))
df
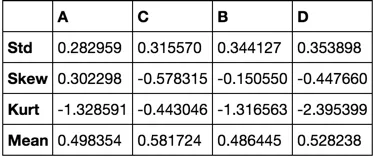
def describe(df):
funcs = dict(Kurt=lambda x: x.kurt(),
Skew='skew',
Mean='mean',
Std='std')
one_group = [True for _ in df.index]
funcs_for_all = {k: funcs for k in df.columns}
return df.groupby(one_group).agg(funcs_for_all).iloc[0].unstack().T
describe(df)
问题
我应该如何完成这个任务?
Dataframe.describe()怎么样?它不符合你的需求吗? - ysearkaselect count(*), mean(foo) from bar的类比,它隐式地对所有内容进行分组,而没有显式的groupby。我有点惊讶你不能只是做bar.agg(...),但最终得到了与下面相同的解决方案。如果对谷歌有帮助,我搜索了像“pandas agg without groupby”或“pandas groupby overall entire dataframe”这样的东西。 - patricksurry