我有这样的 df:
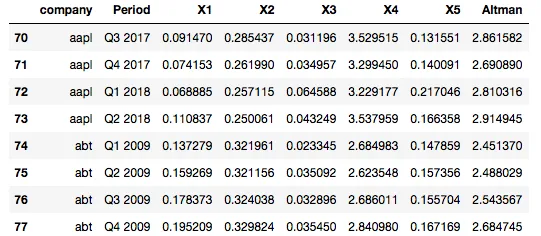
我需要计算每个公司的 X1,X2,X3,X4 和 X5 之间的差值,但我只知道如何计算整列之间的差异。
df['dX1'] = df['X1'].shift(-1) - df['X1']
df['dX2'] = df['X2'].shift(-1) - df['X2']
df['dX3'] = df['X3'].shift(-1) - df['X3']
...
这是一种错误的方法,因为它在第74行用
X1减去第73行的X1(这是两个不同的公司,毫无意义)。我的问题是,如何计算每个期间和每个公司之间的行值差异。例如:
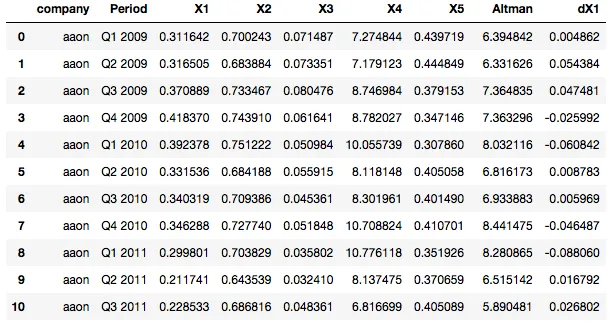 (我可以逐个加载csv文件并为每个公司计算差异,然后将所有内容合并到一个列表中,但这需要2天时间,因为我有700个csv文件。)
(我可以逐个加载csv文件并为每个公司计算差异,然后将所有内容合并到一个列表中,但这需要2天时间,因为我有700个csv文件。)
diff(-1),因为最后一行应该是 None,谢谢。 - dejanmarich