我有一个数据框,例如:
什么是最好和高效的方法呢?
TXN_ID TXN_DATE TXN_TYPE
8C083F30C0674A72 01/01/2013 00:00 A
B610D7D4E2D14513 01/01/2013 00:00 B
698C5DD423AC42D6 02/01/2013 00:00 C
37E2B21583F949CA 12/01/2013 00:00 A
9FE25A547F964E93 13/01/2013 00:00 B
F6C14D987D584E53 14/01/2013 00:00 A
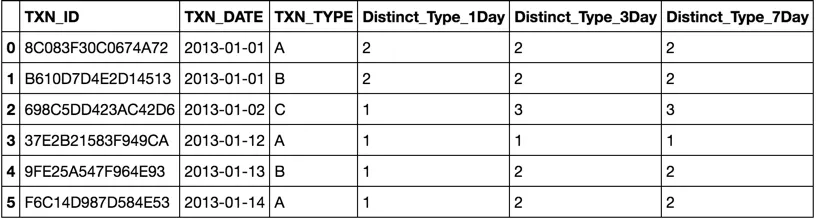
对于每一行,我想要添加三个特征 - 统计在同一天、过去3天和过去1周内TXN_TYPE的不同值数量。因此数据框应如下所示:
TXN_ID TXN_DATE TXN_TYPE Distinct_Type_1Day Distinct_Type_3Day Distinct_Type_7Day
8C083F30C0674A72 01/01/2013 00:00 A 2 2 2
B610D7D4E2D14513 01/01/2013 00:00 B 2 2 2
698C5DD423AC42D6 02/01/2013 00:00 C 1 3 3
37E2B21583F949CA 12/01/2013 00:00 A 1 1 1
9FE25A547F964E93 13/01/2013 00:00 B 1 2 2
F6C14D987D584E53 14/01/2013 00:00 A 1 2 2
什么是最好和高效的方法呢?