我正在尝试使用Python 2.7将一堆文件名中的德语umlauts替换为其他字符。 我使用以下代码获取所有具有umlauts名称的文件列表:
# -*- coding: utf-8 -*-
import os
def GetFilepaths_umlaut(directory):
file_paths = []
umlauts = ["Ä", "Ü", "Ö", "ä", "ö", "ü"]
for root, directories, files in os.walk(directory):
for filename in files:
filepath = os.path.join(root, filename)
if any(umlaut in filepath for umlaut in filepath):
file_paths.append(filepath)
print file_paths
return file_paths
GetFilepaths_umlaut(r'C:\Scripts\Replace Characters\Umlauts')
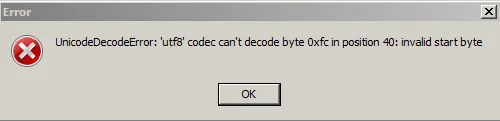
但是当列表被打印到控制台时,它没有打印umlauts(参见截图)。我尝试使用encode(),但出现了第二个截图中显示的错误。我做错了什么?任何反馈都将不胜感激!

使用encode()处理文件路径:
umlauts似乎没有被使用,可能是由于拼写错误。any(umlaut in filepath for umlaut in filepath)看起来很可疑。 - skyking