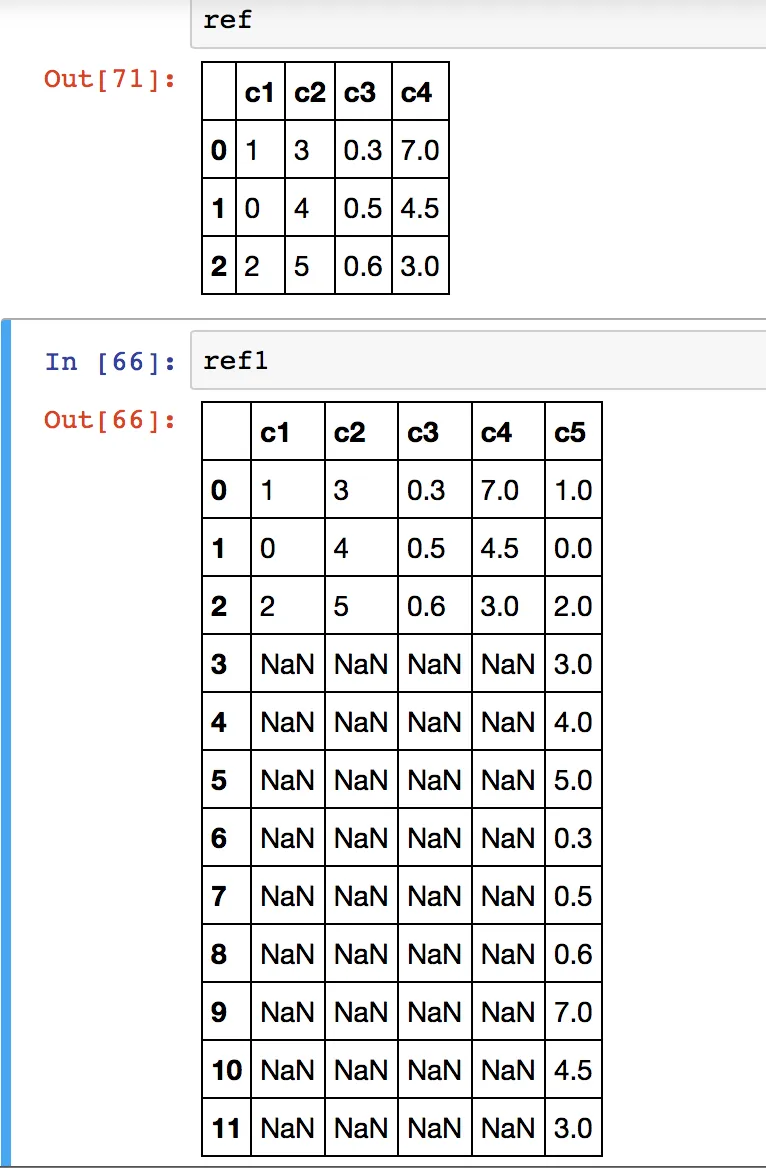
使用
join +
ravel('F'):
ref.join(pd.Series(ref.values.ravel('F')).to_frame('c5'), how='right')
使用
join +
T.ravel():
ref.join(pd.Series(ref.values.T.ravel()).to_frame('c5'), how='right')
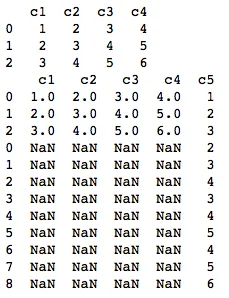
pd.concat + T.stack() + rename
pd.concat([ref, ref.T.stack().reset_index(drop=True).rename('c5')], axis=1)
太多的转置加上“追加”操作
ref.T.append(ref.T.stack().reset_index(drop=True).rename('c5')).T
combine_first + ravel('F')是我最喜欢的组合。
ref.combine_first(pd.Series(ref.values.ravel('F')).to_frame('c5'))
所有产量
c1 c2 c3 c4 c5
0 1.0 3.0 0.3 7.0 1.0
1 0.0 4.0 0.5 4.5 0.0
2 2.0 5.0 0.6 3.0 2.0
3 NaN NaN NaN NaN 3.0
4 NaN NaN NaN NaN 4.0
5 NaN NaN NaN NaN 5.0
6 NaN NaN NaN NaN 0.3
7 NaN NaN NaN NaN 0.5
8 NaN NaN NaN NaN 0.6
9 NaN NaN NaN NaN 7.0
10 NaN NaN NaN NaN 4.5
11 NaN NaN NaN NaN 3.0