我正在尝试从我的数据框中删除一行,其中一个列的值为null。大部分帮助都与删除NaN值有关,但到目前为止这对我没有起作用。
这里我已经创建了数据框:
# successfully crated data frame
df1 = ut.get_data(symbols, dates) # column heads are 'SPY', 'BBD'
# can't get rid of row containing null val in column BBD
# tried each of these with the others commented out but always had an
# error or sometimes I was able to get a new column of boolean values
# but i just want to drop the row
df1 = pd.notnull(df1['BBD']) # drops rows with null val, not working
df1 = df1.drop(2010-05-04, axis=0)
df1 = df1[df1.'BBD' != null]
df1 = df1.dropna(subset=['BBD'])
df1 = pd.notnull(df1.BBD)
# I know the date to drop but still wasn't able to drop the row
df1.drop([2015-10-30])
df1.drop(['2015-10-30'])
df1.drop([2015-10-30], axis=0)
df1.drop(['2015-10-30'], axis=0)
with pd.option_context('display.max_row', None):
print(df1)
这是我的输出:
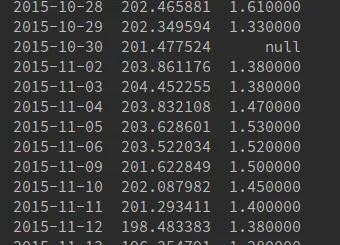
请问有人能告诉我如何删除这一行,最好是通过识别空值来删除以及如何按日期删除?
我还没有太长时间使用pandas,我已经卡了一个小时了。任何建议都将不胜感激。