我从这里了解了卷积神经网络。然后我开始尝试使用torch7编程。我对CNN的卷积层感到困惑。
根据教程,
1
一层神经元只会与其前面的一个小区域连接,而不是以全连接的方式与所有神经元连接。2
例如,假设输入体积的大小为[32x32x3](例如,一个RGB CIFAR-10图像)。如果感受野的大小为5x5,则卷积层中的每个神经元将具有与输入体积中的[5x5x3]区域相关联的权重,总共使用5*5*3 = 75个权重。3
如果输入层是[32x32x3],CONV层将计算与输入中的局部区域相连的神经元的输出,每个神经元在其权重和与其连接到的输入体积的区域之间计算点积。这可能导致诸如[32x32x12]的体积。
我开始尝试使用CONV层对图像进行处理。我在torch7中实现了这个功能。这是我的实现:require 'image'
require 'nn'
i = image.lena()
model = nn.Sequential()
model:add(nn.SpatialConvolutionMM(3, 10, 5, 5)) --depth = 3, #output layer = 10, filter = 5x5
res = model:forward(i)
itorch.image(res)
print(#i)
print(#res)
输出

3
512
512
[torch.LongStorage of size 3]
10
508
508
[torch.LongStorage of size 3]
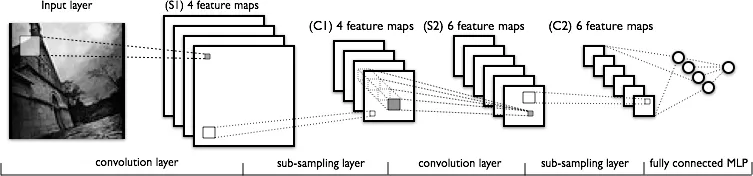
现在让我们看一下CNN的结构。
所以,我的问题是:
问题1
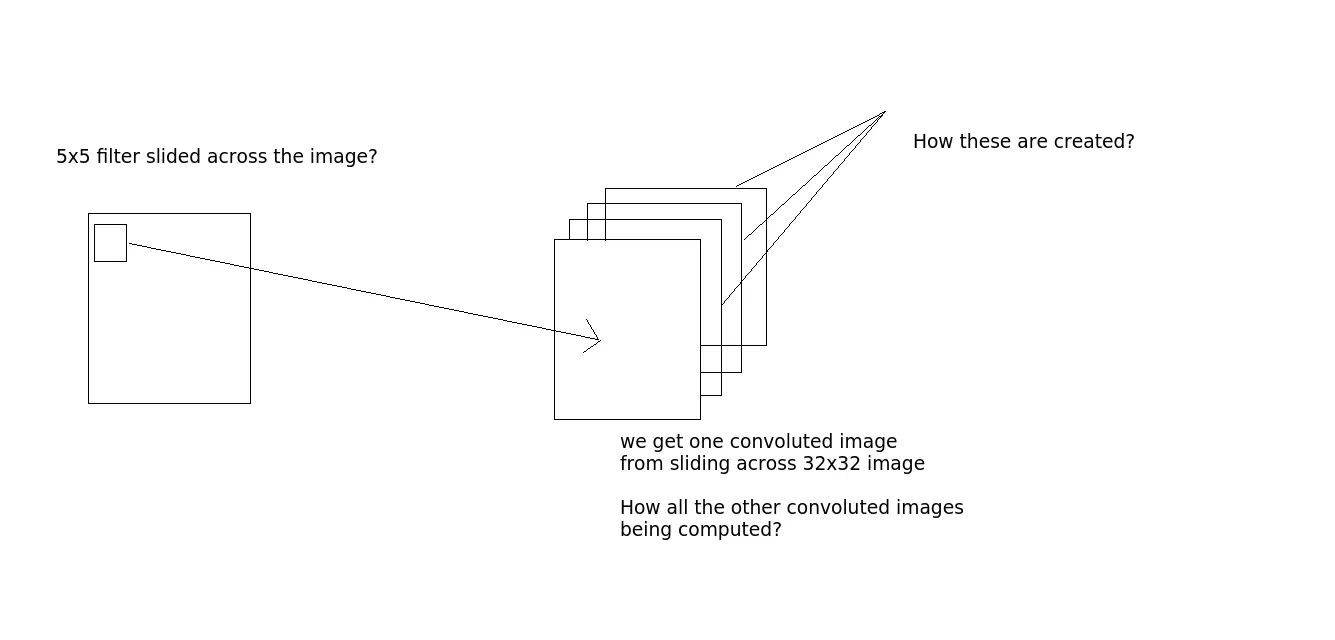
卷积是否像这样进行 - 假设我们取一张32x32x3的图像。然后有一个5x5的滤波器。那么5x5的滤波器将通过整个32x32的图像并产生卷积图像?好的,所以滑动5x5的滤波器穿过整个图像,我们得到一个图像,如果有10个输出层,我们就得到10个图像(从输出中可以看出)。我们如何获得这些图像?(如果需要,请参见图像以了解更多信息)
问题2
卷积层中的神经元数量是多少?它是输出层的数量吗?在我上面编写的代码中,model:add(nn.SpatialConvolutionMM(3, 10, 5, 5))。它是10吗?(输出层数量?)
如果是这样,那么第二点就没有任何意义了。根据那个 如果接受区域的大小为5x5,则卷积层中的每个神经元将具有与输入体积中的[5x5x3]区域的权重,总共为5*5*3 = 75权重。 那么这里的权重是什么?我非常困惑。在torch中定义的模型中没有权重。所以权重在这里起到了什么作用?
有人能解释一下发生了什么吗?
