https://goo.gl/4bRGNh
int swap(int b) {
return __builtin_bswap16(b);
}
变成
swap(int):
rev16 r0, r0
uxth r0, r0
bx lr
所以你的代码可以写成(gcc-explorer: https://goo.gl/HFLdMb)
void fast_Reorder16bit(const uint16_t * src, size_t size, uint16_t * dst)
{
assert(size%2 == 0);
for(size_t i = 0; i < size; i++)
dst[i] = __builtin_bswap16(src[i]);
}
这应该生成循环
.L13:
ldrh r4, [r0, r3]
rev16 r4, r4
strh r4, [r2, r3] @ movhi
adds r3, r3, #2
cmp r3, r1
bne .L13
请访问GCC内置文档,了解更多关于__builtin_bswap16的信息。
Neon建议(经过测试,gcc-explorer: https://goo.gl/fLNYuc):
void neon_Reorder16bit(const uint8_t * src, size_t size, uint8_t * dst)
{
assert(size%16 == 0);
for (size_t i = 0; i < size; i += 16)
vst1q_u8(dst + i, vrev16q_u8(vld1q_u8(src + i)));
}
变成
.L23:
adds r5, r0, r3
adds r4, r2, r3
adds r3, r3, #16
vld1.8 {d16-d17}, [r5]
cmp r1, r3
vrev16.8 q8, q8
vst1.8 {d16-d17}, [r4]
bhi .L23
在这里查看有关neon内部函数的更多信息:https://gcc.gnu.org/onlinedocs/gcc-4.4.1/gcc/ARM-NEON-Intrinsics.html
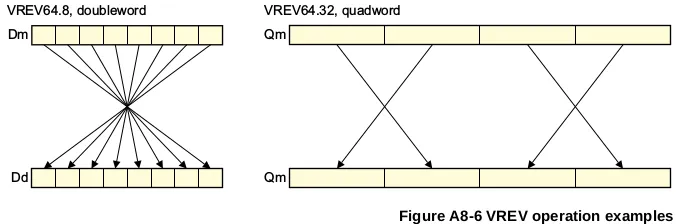
来自ARM ARM A8.8.386的奖励:
VREV16(半字中的矢量反转)将向量中每个半字节的8位元素顺序颠倒,并将结果放置在相应的目标向量中。
VREV32(字中的矢量反转)将向量中每个字节或16位元素的顺序颠倒,并将结果放置在相应的目标向量中。
VREV64(双字中的矢量反转)将向量中每个双字节的8位、16位或32位元素顺序颠倒,并将结果放置在相应的目标向量中。
除了大小之外,没有数据类型区别。
bswap。或者在GCC中使用__builtin_bswap。 - Jon Purdyconst限定符,这正是不使用C风格强制类型转换的原因。你已经有了一个字节数组,为什么要从可能未对齐的地址中提取更大的类型,只是为了将字节在该更大类型内部移位并重新存储它们?只需考虑输入数组中的每个字节应该放在输出数组的哪个字节位置即可! - Ulrich EckhardtReorder16bit代码违反了严格别名规则。你需要使用-fno-strict-aliasing并添加一个对齐检查,以确保正确操作,但这可能会减慢其余代码的运行速度。更好的选择是编写简单、正确的代码并告诉编译器进行优化,这就是编译器存在的目的。 - M.M