所以这里有几件事情要处理。首先,您的数据集似乎具有pH vs.深度。因此,虽然有约2.5百万行,但只有约20万行深度为0-仍然很多。
其次,要获取到最近海岸的距离,您需要一个海岸线的shapefile。幸运的是,这可以在优秀的
Natural Earth website上找到
here。
第三,你的数据是以经纬度表示的(因此单位为度),但你需要以公里表示距离,所以你需要对数据进行转换(上面的海岸线数据也是以经纬度表示的,同样需要转换)。转换的一个问题在于,你的数据显然是全球性的,而任何全球性的转换都必然是非平面的。因此精度将取决于实际位置。正确的做法是对数据进行网格化处理,然后使用适用于点所在网格的一组平面变换。虽然如此,但这超出了本问题的范围,因此我们将使用一个全局变换(莫尔韦德投影),只是为了让你了解在R中如何完成它。
library(rgdal)
library(rgeos)
setwd(" < directory with all your files > ")
wgs.84 <- "+proj=longlat +datum=WGS84 +no_defs +ellps=WGS84 +towgs84=0,0,0"
mollweide <- "+proj=moll +lon_0=0 +x_0=0 +y_0=0 +ellps=WGS84 +datum=WGS84 +units=m +no_defs"
df <- read.csv("OSD_All.csv")
sp.points <- SpatialPoints(df[df$Depth==0,c("Long","Lat")], proj4string=CRS(wgs.84))
coast <- readOGR(dsn=".",layer="ne_10m_coastline",p4s=wgs.84)
coast.moll <- spTransform(coast,CRS(mollweide))
point.moll <- spTransform(sp.points,CRS(mollweide))
set.seed(1)
test <- sample(1:length(sp.points),10)
result <- sapply(test,function(i)gDistance(point.moll[i],coast.moll))
result/1000
plot(coast)
points(sp.points[test],pch=20,col="red")
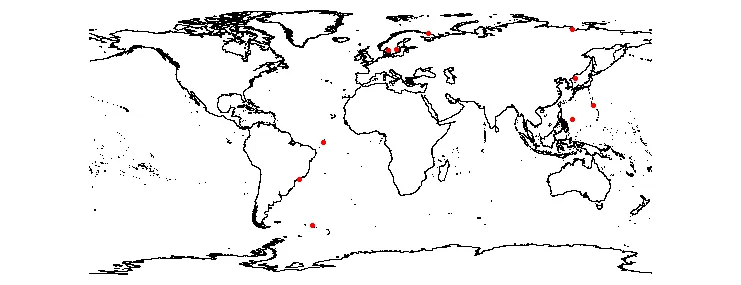
所以这个代码会读取你的数据集,提取出
Depth==0的行,并将其转换为SpatialPoints对象。然后,我们将从上面链接下载的海岸线数据库读入一个SpatialLines对象。接着,我们使用
spTransform(...)将两者都转换为Mollweide投影,然后使用
rgeos包中的
gDistance(...)计算每个点与最近海岸之间的最小距离。
再次强调,尽管有许多小数位,这些距离仅仅是近似值。
一个非常大的问题是速度:这个过程需要约2分钟才能计算1000个距离(在我的系统上),因此要运行所有200,000个距离需要大约6.7小时。理论上,一个选择是找到一个分辨率更低的海岸线数据库。
下面的代码将计算所有201,000个距离。
result <- sapply(1:length(sp.points), function(i)gDistance(sp.points[i],coast))
编辑: 根据楼主有关核心的评论,我开始思考这可能是一个值得并行化改进的实例。因此,以下是在Windows上使用并行处理运行此程序的方法。
library(foreach)
library(snow)
library(doSNOW)
cl <- makeCluster(4,type="SOCK")
registerDoSNOW(cl)
get.dist.parallel <- function(n) {
foreach(i=1:n, .combine=c, .packages="rgeos", .inorder=TRUE,
.export=c("point.moll","coast.moll")) %dopar% gDistance(point.moll[i],coast.moll)
}
get.dist.seq <- function(n) sapply(1:n,function(i)gDistance(point.moll[i],coast.moll))
identical(get.dist.seq(10),get.dist.parallel(10))
library(microbenchmark)
microbenchmark(get.dist.seq(1000),get.dist.parallel(1000),times=1)
使用4个核心可以将处理速度提高约3倍。因此,由于1000个距离需要大约1分钟,所以100,000个距离应该只需要不到2小时。
请注意,使用
times=1实际上是对
microbenchmark(...)的滥用,因为整个过程的重点是运行多次并平均结果,但我没有耐心等待。