为什么Python看起来平均比C/C++慢?我学习Python作为我的第一门编程语言,但是我刚开始学习C++就感觉到了明显的差异。
为什么Python程序通常比用C或C++编写的等效程序慢?
93
- Riemannliness
4
21你知道Python是解释性语言吗? - S.Lott
11@kaizer.se - 那么我们还需要说出其他显而易见的事实,我们不是在使用编程语言,而是在使用编程语言的实现;等等。 - igouy
7@kaizer.se:是的,我们知道,我们知道。但想想在避免像你这样的评论的情况下写作有多尴尬。“为什么Python代码(使用任何常见解释器运行)如此缓慢?” - Cascabel
6在经过多次讨论后,这个问题得到了第二次机会。我编辑了语气以防止它被(重新)关闭和(重新)删除。令我惊讶的是,这个问题的1000位观看者中没有一位看到争议关闭原因或采取行动修复这个有争议的问题语气,尽管其中许多人投票支持了问题或答案。 - ire_and_curses
11个回答
112
Python是比C更高级的语言,这意味着它会将计算机的细节——如内存管理、指针等——抽象出来,让你可以以更接近人类思维方式的方式编写程序。
确实,仅考虑执行时间时,C代码通常比Python代码运行速度快10到100倍。然而,如果你还考虑开发时间,Python往往能够击败C。对于许多项目而言,开发时间比运行时间表现更为关键。较长的开发时间直接转化为额外的成本、更少的功能和缓慢的上市时间。
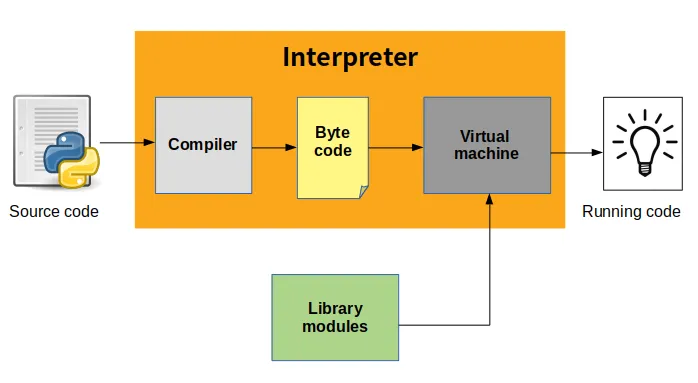
Python代码执行速度较慢的内部原因是因为代码在运行时进行解释,而不是在编译时被编译成本地代码。
其他解释型语言(如Java字节码和.NET字节码)比Python运行速度更快,因为标准发行版包括一个JIT编译器,该编译器在运行时将字节码编译为本地代码。CPython没有 JIT 编译器的原因是 Python 的动态性使得编写 JIT 编译器变得困难。目前有一些工作正在进行,以编写更快的 Python 运行时,因此您应该期望未来性能差距会缩小,但在标准的 Python 发行版中包含一个功能强大的 JIT 编译器之前,可能还需要一段时间。
- Mark Byers
11
46严格来说:Python在编译时通常不会被编译成本地代码。Python字节码仍然需要被解释执行。 - Mark Byers
22为什么 Python 实现往往需要占用大量 CPU 的原因并没有得到解释。你可以在运行时以相对较小的成本抽象出所有这些,但正是 Python 非常动态的特性消耗了所有的 CPU:所有这些属性查找和方法派发都累积起来,即使是 JIT 也会遇到相当大的困难——而 Python 目前通常不使用 JIT。 - SamB
3回顾过去,我认为值得注意的是全局解释器锁以及 Python 中的所有对象都是堆分配对象,即使是一个简单的整数。不涉及具体实现细节,这些类型的事情除了更高层次的抽象外,仍然会对性能产生相当大的影响。尽管如此,我仍然认为大多数应用程序应该主要使用像 Python 这样的脚本语言编写。正如 Knuth 所说的关于过早优化,大多数应用程序只有很少部分是非常关键的性能点。 - stinky472
这可能有关系,但如果解释得那么慢,那么Node.js的速度不会比Python快多少,甚至可能更慢。 - Triforcey
3我非常好奇你所说的“是因为Python语言的动态特性使得编写一个这样的东西很困难。” 你所提到的“动态”是什么意思? - jokoon
显示剩余6条评论
56
CPython的速度较慢,因为它没有即时编译器(由于它是参考实现,在某些情况下选择简单而不是性能)。Unladen Swallow 是一个项目,旨在将基于LLVM的JIT添加到CPython中,并实现了大量的加速。Jython和IronPython可能也比CPython快得多,因为它们支持高度优化的虚拟机(JVM和.NET CLR)。
然而,一个显然会使Python变慢的因素是它是动态类型语言,并且每个属性访问都需要进行大量查找。
例如,在对象A上调用f会导致可能在__dict__中进行查找、调用__getattr__等,最终调用可调用对象f的__call__方法。
关于动态类型,如果你知道你正在处理的数据类型,有许多优化可以完成。例如,在Java或C中,如果你有一个整数数组要求和,最终汇编代码可能只需要从索引i处获取值,将其与累加器相加,然后递增i。
在Python中,这很难使代码达到这种最佳状态。假设你有一个包含int的列表子类对象。在添加之前,Python必须调用list.__getitem__(i),然后通过调用accumulator.__add__(n)将其添加到“累加器”中,然后重复这个过程。这里可能会发生大量的备选查找,因为另一个线程可能已经更改了例如__getitem__方法、列表实例的字典或类的字典等。甚至在本地命名空间中查找累加器和列表(以及任何你正在使用的变量)也需要进行字典查找。对于使用任何用户定义的对象,这种开销都适用,尽管对于一些内置类型来说,它会有所缓解。
sum(list) 而不是使用累加器和索引。坚持使用这些类型,并进行一些数字计算,例如使用 int/float/complex 类型,通常不会出现速度问题。如果确实存在性能瓶颈,则可能有一个关键的时间敏感单元(例如 SHA2 摘要函数),您可以将其简单地移植到 C 代码(或 Jython 中的 Java 代码)中。事实是,当您编写 C 或 C++ 代码时,您将浪费大量时间来完成您可以在几秒钟/几行 Python 代码中完成的事情。我认为这种权衡总是值得的,除非您正在做嵌入式或实时编程等无法承受的情况。- L̲̳o̲̳̳n̲̳̳g̲̳̳p̲̳o̲̳̳k̲̳̳e̲̳̳
3
Unladen Swallow目前使用的内存稍微多一些,2009年Q2的结果表明内存增加了10倍,而2009年Q3的结果表明他们将其降低了930%(不确定如何解释这个数字)。听起来像是更低的内存是一个目标,但尚未实现。 - Brendan Long
糟糕,我写的那句话根本没有意义。 - L̲̳o̲̳̳n̲̳̳g̲̳̳p̲̳o̲̳̳k̲̳̳e̲̳̳
在某种程度上,可能会使 Python 变慢的一件事是它的动态类型,每个属性访问都有大量查找。这实际上就是 PyPy 中的 JIT 获胜的地方。JIT 可以注意到你的代码正在执行一些简单的、不复杂的操作,并可以优化成一些简单的机器指令。因此,每当你在循环中进行简单操作时,PyPy 现在比 CPython 快得多。 - steveha
30
编译与解释在这里并不重要:Python是经过编译的,对于任何非平凡程序来说,它只是运行时成本的一小部分。
主要成本包括:缺乏与本地整数相对应的整数类型(使所有整数操作变得更加昂贵)、缺乏静态类型(使方法解析更加困难,并意味着必须在运行时检查值的类型)以及缺乏未装箱的值(可以减少内存使用量,并避免一级间接性)。
并不是说这些事情在Python中不可能或不能更有效地实现,而是选择了方便和灵活性以及语言清晰度优先于运行时速度。一些聪明的JIT编译可能会克服其中一些成本,但Python提供的好处总是伴随着一些成本。
- user97370
1
2比被接受的答案更好,尽管需要注意的是Python并不总是编译的。实际上,它更多地是在我的经验中被解释执行。 - Triforcey
8
Python和C之间的区别通常是解释型(字节码)和编译型(本地代码)语言之间的区别。个人认为,我并不认为Python很慢,它表现得相当不错。如果您尝试在其领域之外使用它,当然它会变慢。但是,您可以为Python编写C扩展程序,将时间关键的算法放入本地代码中,从而使其更快。
- Femaref
3
2s/it's/its。在可优化性方面,解释型和编译型并没有任何区别。JVM 和 C 可以是解释型或编译型。在任一情况下都可以应用不同的优化(自适应优化 vs 编译时 + LTO)。 - L̲̳o̲̳̳n̲̳̳g̲̳̳p̲̳o̲̳̳k̲̳̳e̲̳̳
4Python编译成字节码后被解释执行,也可以编译成机器码,因此实际上我们都没有说错。 - Femaref
2除了不完全正确之外,这个答案没有谈到真正的问题,@Longpoke在他的回答中解释得相当好。 - SamB
5
将C/C++与Python进行比较并不公平,就像比较一辆F1赛车和一辆实用卡车一样。
令人惊讶的是,Python相对于其他动态语言同类而言速度是如此之快。虽然方法通常被认为存在缺陷,但可以查看The Computer Language Benchmark Game以查看类似算法的相对语言速度。
与Perl、Ruby和C#的比较更加“公平”。
令人惊讶的是,Python相对于其他动态语言同类而言速度是如此之快。虽然方法通常被认为存在缺陷,但可以查看The Computer Language Benchmark Game以查看类似算法的相对语言速度。
与Perl、Ruby和C#的比较更加“公平”。
- dawg
30
5我更喜欢用兰博基尼飞驰去上班的比喻来表示非内存安全语言,而遵守限速规定的街车则代表内存安全语言。 :) - L̲̳o̲̳̳n̲̳̳g̲̳̳p̲̳o̲̳̳k̲̳̳e̲̳̳
5对我来说,C更像是一辆火箭车 - 如果你想直线行驶且附近没有障碍物,那就太棒了!否则就不是那么理想了。 - SamB
1@igouy 在 Debian 赞助之前,“The Great Computer Language Shootout” 是该项目的名称。您仍然可以使用这个名称在 Google 上找到它,还有一些类似的名称,比如 http://dada.perl.it/shootout/index.html。 - dawg
1@igouy:你说得对:那里的Perl代码已于2010年5月更新为多线程。但是等等!你声称“自2001年以来没有更新的网站”,但你指向的页面却是2010年5月的。一些Perl作者必须比最新的Perl版本更快地生成所需的输出。哦,但糟糕了!你声称它不是基于输出!那么除了与参考输出的差异之外,它还基于什么?如果您对我发布的帖子或OP有建设性的评论以增加准确性,请告诉我。 - dawg
1请指出一些基于比较程序的语言之间的区别,而这并不完全正确。用丘吉尔的话概括就是: 除了所有其他方法,它是最糟糕的测试方法。;-) 我曾经参与过显卡基准测试,起初我们有一些非常具体的基准测试,可以进行公平的比较,直到制造商真正设计出硬件和驱动程序以便在牺牲整体性能的情况下执行基准测试良好。人们喜欢简单明了的答案:这比那快。有些东西难以找到客观简单的答案。 - dawg
显示剩余25条评论
5
Python通常被实现为一种脚本语言。这意味着它需要通过解释器将代码即时转换成机器语言,而不是从一开始就全部使用机器语言来执行。因此,它需要付出翻译代码的代价,除了执行代码的代价。即使是CPython也是如此,尽管它编译成字节码更接近机器语言,因此可以更快地进行翻译。Python还具有一些非常有用的运行时特性,例如动态类型,但这些东西通常在最高效的实现上也无法实现,因为会带来沉重的运行时成本。
如果你要做非常处理器密集型的工作,比如编写着色器,Python的速度通常会比C++慢大约200倍左右。如果你使用CPython,这个时间可以减半,但仍然远远不够快。所有这些运行时好处都是有代价的。有很多基准测试可以证明这一点,这里有一个特别好的例子。正如主页上所承认的那样,这些基准测试存在缺陷。它们都是由用户提交的,试图以他们选择的编程语言编写高效的代码,但这给你一个很好的一般概念。
如果你关心效率,我建议你尝试将两种语言混合在一起:这样你就可以同时获得两个世界的最佳性能。我主要是C++程序员,但我认为很多人倾向于在C++中编写太多的单调、高级代码,而这只是一个麻烦(编译时间只是一个例子)。将一种脚本语言与像C/C++这样更接近底层的高效语言混合使用,真正是在平衡程序员效率(生产力)和处理效率方面的最佳选择。
如果你要做非常处理器密集型的工作,比如编写着色器,Python的速度通常会比C++慢大约200倍左右。如果你使用CPython,这个时间可以减半,但仍然远远不够快。所有这些运行时好处都是有代价的。有很多基准测试可以证明这一点,这里有一个特别好的例子。正如主页上所承认的那样,这些基准测试存在缺陷。它们都是由用户提交的,试图以他们选择的编程语言编写高效的代码,但这给你一个很好的一般概念。
如果你关心效率,我建议你尝试将两种语言混合在一起:这样你就可以同时获得两个世界的最佳性能。我主要是C++程序员,但我认为很多人倾向于在C++中编写太多的单调、高级代码,而这只是一个麻烦(编译时间只是一个例子)。将一种脚本语言与像C/C++这样更接近底层的高效语言混合使用,真正是在平衡程序员效率(生产力)和处理效率方面的最佳选择。
- stinky472
12
@Mattias:不是的;虽然你说得对,两者都使用字节码,但Java会在执行之前将字节码编译成本地机器语言(可以提前编译或使用JIT编译器)。在某些情况下,Java字节码是某些微处理器的本地机器语言。另一方面,CPython是一个严格的字节码解释器。它会即时进行所有翻译工作,这就是为什么它通常比其他Python实现快两倍,但仍然远不及Java快的原因。 - stinky472
1另外,CPython并不是实时编译,而是实时解释字节码。典型的实现方式会反复重新翻译相同的字节码,例如在循环中。这就是为什么它仍然被认为是一个字节码解释器而不是编译器的原因。CPython会将.py文件即时编译成.pyc文件(Python到字节码),但这是完全不同的事情。pyc只是让解释器更容易阅读和翻译的代码,但它仍然是解释执行的。Java方法更像是混合模式,并不仅仅因为字节码,而是因为它对字节码的处理方式。 - stinky472
@stinky472 >>就像首页所承认的那样,这些基准测试是有缺陷的。<< 你读过“有缺陷的基准测试或错误的思维方式?”页面吗? - igouy
1@igouy 是的,但如果我们太过于追求细节,Python并没有比C语言慢。如果有人花费足够的精力,他们也许能够开发出一些在性能方面可与之媲美的东西,但这种情况通常不会出现。当你使用的是一个动态类型的语言,并且具有只能在运行时实现的机制,如内省时,就会产生运行时成本,即使最好的实现者也无法完全消除这种成本。也许有一天他们会找到一个革命性的新方法。 - stinky472
@igouy“正如首页所承认的那样,基准测试存在缺陷。”不,你甚至不必看得那么远。只需阅读我在回答中指出这一点之前发布链接的内容即可。我也不确定你想表达什么。我的观点是,实际上,如果你在现有的Python实现中编写光线追踪器,无论你有多厉害,你都不会获得与Pixar Renderman相当的速度。 - stinky472
显示剩余7条评论
4
除了已经发布的答案,Python 的一个特点是能够在运行时更改事物,这在其他语言如 C 中是无法做到的。您可以随时向类添加成员函数。
此外,Python 的动态性质使得很难确定将传递给函数的参数类型,进而使优化变得更加困难。 RPython 似乎是解决优化问题的一种方法。
尽管如此,它可能不会像 C 那样快速处理数字计算等任务。
此外,Python 的动态性质使得很难确定将传递给函数的参数类型,进而使优化变得更加困难。 RPython 似乎是解决优化问题的一种方法。
尽管如此,它可能不会像 C 那样快速处理数字计算等任务。
- Mattias Nilsson
3
为什么RPython不能表现得相当好呢?它不是可以直接翻译成C语言吗? - SamB
显然我没有保持自己的更新。甚至有一个基准测试,其中 RPython 打败了 gcc。未来已经来临 :) - Mattias Nilsson
1C语言没有类。你是不是想说C++? - Roman A. Taycher
2
C和C++编译成本地代码,也就是说它们直接在CPU上运行。Python是一种解释型语言,这意味着你编写的Python代码必须经过许多抽象阶段才能变成可执行的机器码。
- Puppy
1
在某些情况下,将Python编译成C++是可能的,因此它有时可以像本地代码一样快。 - Anderson Green
1
这个回答适用于python3。大多数人不知道每次使用import语句时都会发生类似JIT的编译。CPython会搜索导入的源文件(.py),注意修改日期,然后在名为“__pycache__”(dunder pycache dunder)的子文件夹中查找已编译为字节码的文件(.pyc)。如果一切匹配,则您的程序将使用该字节码文件,直到有些东西发生变化(您更改源文件或升级Python)。
但是通常从BASH shell启动的主程序不会发生这种情况,无论是交互式还是通过其他方式启动。下面是一个例子:
但是通常从BASH shell启动的主程序不会发生这种情况,无论是交互式还是通过其他方式启动。下面是一个例子:
#!/usr/bin/python3
# title : /var/www/cgi-bin/name2.py
# author: Neil Rieck
# edit : 2019-10-19
# ==================
import name3 # name3.py will be cache-checked and/or compiled
import name4 # name4.py will be cache-checked and/or compiled
import name5 # name5.py will be cache-checked and/or compiled
#
def main():
#
# code that uses the imported libraries goes here
#
if __name__ == "__main__":
main()
#
一旦执行完成,编译输出的代码将被丢弃。然而,如果您通过类似以下导入语句启动,则您的主要Python程序将被编译:
#!/usr/bin/python3
# title : /var/www/cgi-bin/name1
# author: Neil Rieck
# edit : 2019-10-19
# ==================
import name2 # name2.py will be cache-checked and/or compiled
#name2.main() #
现在说一下注意事项:
- 如果您在Apache区域交互地测试代码,则编译的文件可能会保存具有Apache无法读取(或重新编译时无法写入)的权限。
- 有人声称子文件夹“__pycache__”(dunder pycache dunder)需要在Apache配置中可用。
- SELinux是否允许CPython写入子文件夹(这是CentOS-7.5中的问题,但我相信已经提供了补丁)?
最后一点。您可以自己访问编译器,生成pyc文件,然后更改保护位以解决我列出的任何注意事项。以下是两个示例:
method #1
=========
python3
import py_compile
py_compile("name1.py")
exit()
method #2
=========
python3 -m py_compile name1.py
- neilrieck
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接