问题:
给定一个由N个节点和M条边组成的图,边的索引范围为1 -> M。保证任意两个节点之间都有路径。
您需要为M条边分配权重。 权重的范围在[1 ... M]之间,并且每个数字只能出现一次。
简而言之,答案应该是[1...M]的排列数组,其中arr[i] = x表示边[i]的权重为x。
您将获得n-1条边的集合R。 R保证是图的生成树。
找到一种分配权重的方式,使得R成为图的最小生成树;如果有多个答案,请打印字典序最小的一个。
限制条件:
N, M <= 10^6
例子:
边缘:
3 4
1 2
2 3
1 3
1 4
R = [2, 4, 5]
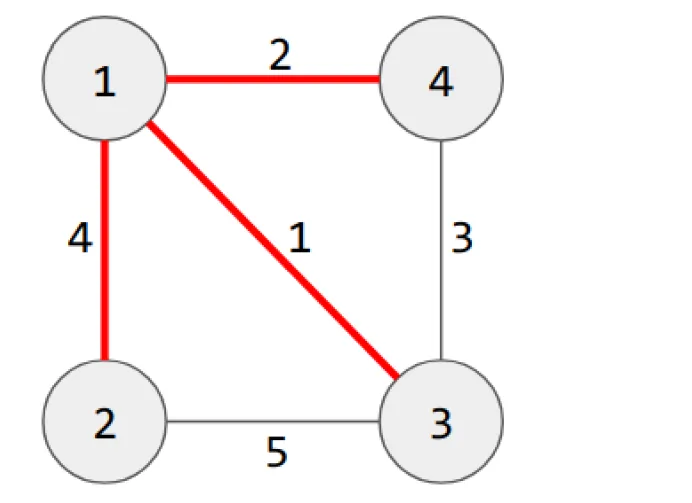
Answer: 3 4 5 1 2
说明:
如果你对上面的图中的图形分配权重,MST 将是集合 R,并且它具有最小的字典顺序。
我使用 O(N^2) 的方法:
由于需要最小字典顺序,我遍历边的列表,按递增顺序分配权值。最初,w = 1。可能有三种情况:
- 如果 edge[i] 在 R 中,则将 weight[i] 赋值为 w,将 w 增加 1
- 如果 edge[i] 不在 R 中:假设 edge[i] 连接节点 u 和 v。为了 R 中从 u 到 v 的每条边(如果该边尚未分配)分配权值并增加 w。然后为 edge[i] 分配权重并增加 w。
- 如果 edge[i] 已经分配,跳过它。
是否有任何方法可以改进我的解决方案,使其可以在 O(N.logN) 或更少的时间内工作?