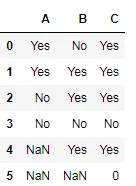
我有一个包含两列数据的pandas数据框,如下所示:
A B
Yes No
Yes Yes
No Yes
No No
NA Yes
NA NA
我希望根据这些值创建一个新列,如果任何列的值为Yes,则新列中的值也应为Yes。 如果两个列的值都是No,那么新列的值也将为No。 最后,如果两个列的值都为NA,则新列的输出也将为NA。 上述数据的示例输出如下:
C
Yes
Yes
Yes
No
Yes
NA
我编写了一个循环遍历数据框的长度,并检查每个值以获取新列。 但是,处理1000万条记录需要很长时间。 有没有更快的 Pythonic 方法来实现这一点?