这两者之间有哪些关键区别?
Rcpp 中的
*Vector 和
*Matrix 类作为
R 的
SEXP 表示的封装,例如指向数据的指针。有关详细信息,请参见
R Internals 的
Section 1.1 SEXPs。
Rcpp 的设计利用这一点,通过构造包含指向数据的指针的类的
C++ 对象。这促进了两个关键特点:
- 无缝传输 R 和 C++ 对象,以及
- 在 R 和 C++ 之间传输成本低,因为只传递一个指针。
与此同时,
arma对象类似于传统的
std::vector<T>,在
R和
C++对象之间进行
深度复制。但是,有一个例外,即
高级构造函数的存在,它允许在
armadillo对象结构内部
重用R对象后面的内存。因此,如果您不小心,可能会在从
R到
C++及其反向转换时产生不必要的惩罚。
注意:允许重用内存的高级构造函数并不存在于
arma::sp_mat中。因此,使用稀疏矩阵的引用可能不会产生所需的加速效果,因为从
R到
C++和反向转换时会执行复制。
您可以根据“按引用传递”或“按副本传递”的范例来查看差异。为了理解代码以外的区别,请考虑
mathwarehouse的以下GIF:

为了在代码中说明这种情况,考虑以下三个函数:
#include <RcppArmadillo.h>
void memory_reference_double_ex(arma::vec& x, double value) {
x.fill(value);
}
void memory_reference_int_ex(arma::ivec& x, int value) {
x.fill(value);
}
arma::vec memory_copy_ex(arma::vec x, int value) {
x.fill(value);
return x;
}
两个函数
memory_reference_double_ex()和
memory_reference_int_ex()会更新对象
R内部,假设适当的
数据类型存在。因此,我们可以通过在定义中指定
void来避免返回值,因为由
x分配的内存正在被
重复使用。第三个函数
memory_copy_ex()需要一个返回类型,因为它通过复制传递,因此没有重新分配调用就
不会修改现有存储。强调一下:
x向量将通过引用传递到C++中,例如在arma::vec&或arma::ivec&的末尾添加&,并且x在R中的类别是double或integer,这意味着我们匹配了arma::vec的底层类型,例如Col<double>,或arma::ivec,例如Col<int>。
让我们快速看两个例子。
在第一个示例中,我们将查看运行memory_reference_double_ex()和memory_copy_ex()生成的结果并进行比较。请注意,在R和C ++ 中定义的对象之间的类型是相同的(例如double)。在下一个示例中,这将不成立。
x = c(0.1, 2.3, 4.8, 9.1)
typeof(x)
x
memory_reference_double_ex(x, value = 9)
x
a = memory_copy_ex(x, value = 3)
x
a
现在,如果R对象的底层类型是整数而不是双精度浮点数会发生什么?
x = c(1L, 2L, 3L, 4L)
typeof(x)
x
memory_reference_double_ex(x, value = 9)
x
发生了什么?为什么
x没有更新?幕后,
Rcpp创建了一个新的内存分配,这是正确的类型——
double而不是
int——然后传递给
armadillo。这导致两个对象之间的引用“链接”不同。
如果我们在
armadillo向量中使用整数数据类型,注意我们现在有了先前给出的相同效果:
memory_reference_int_ex(x, value = 3)
x
这引发了对这两种范式有用性的讨论。由于在使用C++时,{{速度}}是首选的基准,因此让我们从基准的角度来看待这个问题。
考虑以下两个函数:
#include <RcppArmadillo.h>
void copy_double_ex(arma::vec x, double value) {
x.fill(value);
}
void reference_double_ex(arma::vec& x, double value) {
x.fill(value);
}
对它们进行微基准测试的结果如下:
library("microbenchmark")
x = rep(1, 1e8)
micro_timings = microbenchmark(copy_double_ex(x, value = 9.0),
reference_double_ex(x, value = 9.0))
autoplot(micro_timings)
micro_timings
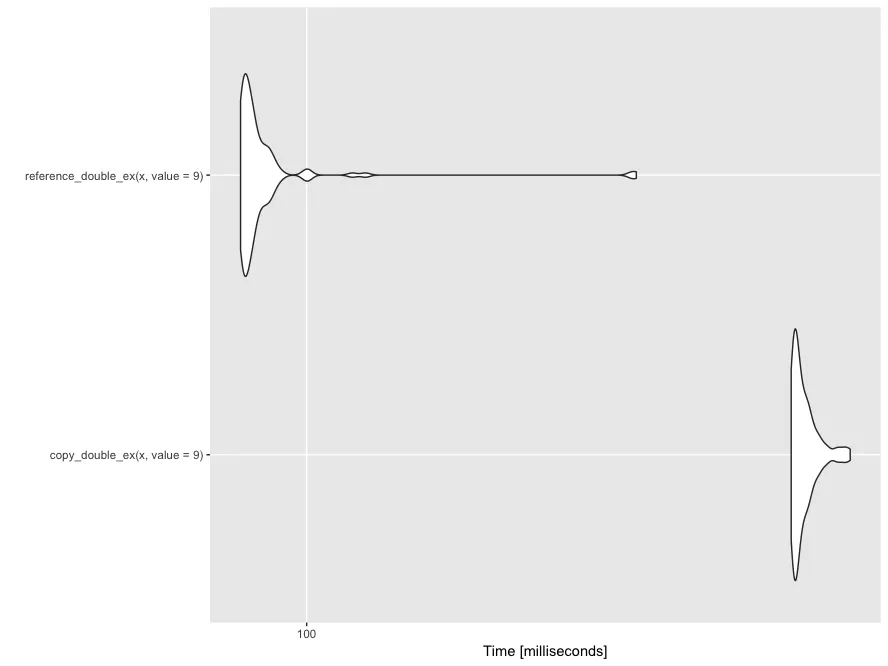
注意: 与复制范例相比,所引用的对象每次迭代速度大约快了6.509771倍,因为我们不必重新分配和填充那块内存。
何时使用哪个?
你需要做什么?
你只是想快速加速依赖于循环但不需要严格线性代数操作的算法吗?
如果是这样,只使用Rcpp就足够了。
你是否试图执行线性代数运算?或者你希望在多个库或计算平台(例如MATLAB、Python、R等)中使用此代码?
如果是这样,你应该在armadillo中编写算法的核心,并设置适当的钩子将函数导出到R中使用Rcpp。
使用其中一个是否具有性能/内存优势?
是的,正如先前指出的,肯定存在性能/内存优势。不仅如此,通过使用RcppArmadillo,你实际上在Rcpp之上添加了一个额外的库,从而增加了整体安装占用空间、编译时间和系统要求(参见macOS构建的困难)。找出你的项目需要什么,然后选择该结构。
它们之间的唯一区别是成员函数吗?
不仅是成员函数,还有:
- 矩阵分解的估算例程
- 计算统计量值
- 对象生成
- 稀疏表示(避免操作S4对象)
这些是Rcpp和armadillo之间的根本不同。一个旨在促进将R对象转换为C ++,而另一个则旨在进行更严格的线性代数计算。这应该很明显,因为Rcpp不实现任何矩阵乘法逻辑,而armadillo使用系统的基本线性代数子程序(BLAS)来执行计算。
作为额外的问题:我应该考虑arma :: colvec或arma :: rowvec吗?
这取决于您希望如何返回结果。您想要一个:1 x N(行向量)还是N x 1(列向量)?默认情况下,RcppArmadillo将这些结构作为具有其适当维度的矩阵对象返回,而不是传统的1D R向量。
例如:
#include <RcppArmadillo.h>
arma::vec col_example(int n) {
arma::vec x = arma::randu<arma::vec>(n);
return x;
}
arma::rowvec row_example(int n) {
arma::rowvec x = arma::randu<arma::rowvec>(n);
return x;
}
测试:
set.seed(1)
col_example(4)
set.seed(1)
row_example(4)