我有以下数据框:
我希望通过每个A计算B的数量,并得出以下结果:
我通常用
更新:
|----|----|
| A | B |
| a1 | b1 |
| a2 | b1 |
| a1 | b2 |
| a2 | b3 |
我希望通过每个A计算B的数量,并得出以下结果:
|----|----|-------|
| A | B | Count |
| a1 | b1 | 1 |
| | b2 | 1 |
| | b3 | NaN |
| a2 | b1 | 1 |
| | b2 | NaN |
| | b3 | 1 |
我通常用
df.groupby([B])[A].count()进行这种操作,但在这种类似数据透视表的情况下,我感到有些困惑。谢谢你提前帮忙。更新:
df.info()。<class 'pandas.core.frame.DataFrame'>
Int64Index: 20422 entries, 180 to 96430
Data columns (total 2 columns):
B 20422 non-null object
A 20422 non-null object
dtypes: object(2)
memory usage: 478.6+ KB
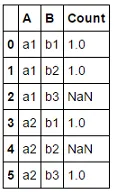
我正在使用 df.groupby([B])[A].value_counts().unstack().stack(dropna=False).reset_index(name="Count"):
|--|----|----|-------|
| | A | B | Count |
|0 | a1 | b1 | 1 |
|1 | a1 | b2 | 1 |
|2 | a1 | b3 | NaN |
|3 | a2 | b1 | 1 |
|4 | a2 | b2 | NaN |
|5 | a2 | b3 | 1 |
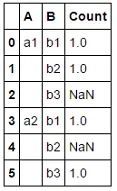
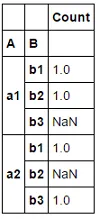
df_g = df.groupby('A')['B'].value_counts().unstack().stack(dropna=False).reset_index(name="Count")df_g.groupby([A, B])['Count'].sum().to_frame()- Novitoll