我正在努力加深对编程语言低级操作的理解,特别是它们如何与操作系统/CPU交互。我可能已经阅读了Stack Overflow上所有堆栈/堆相关线程中的每个答案,它们都很出色。但仍有一件事情我还没有完全明白。
考虑下面这个伪代码函数,它往往是有效的Rust代码 ;-)
fn foo() {
let a = 1;
let b = 2;
let c = 3;
let d = 4;
// line X
doSomething(a, b);
doAnotherThing(c, d);
}
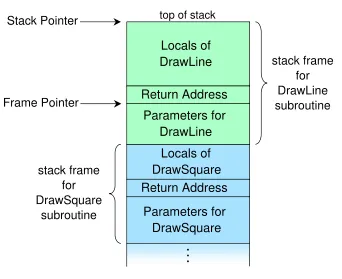
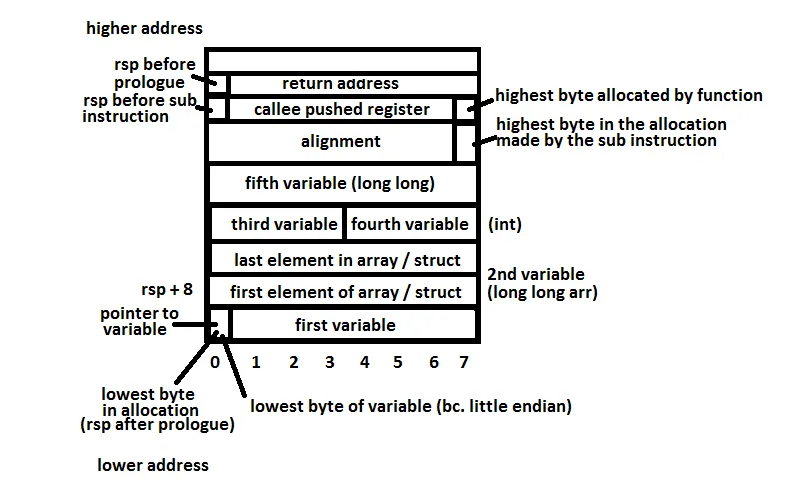
我假设在X行的情况下堆栈的样子如下:
Stack
a +-------------+
| 1 |
b +-------------+
| 2 |
c +-------------+
| 3 |
d +-------------+
| 4 |
+-------------+
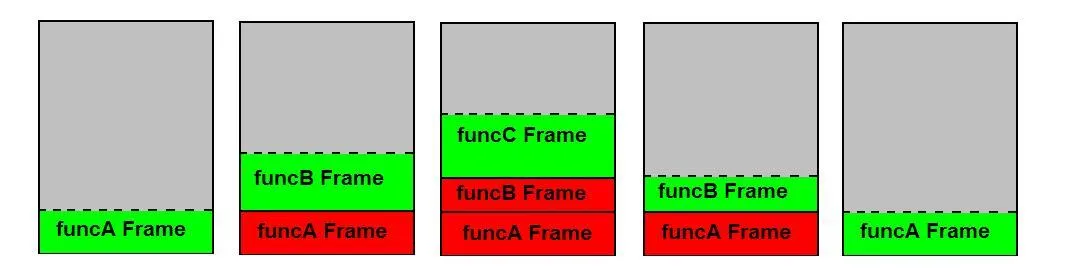
现在,我读到的关于栈如何工作的所有内容都指出它严格遵循LIFO规则(后进先出)。就像.NET、Java或任何其他编程语言中的堆栈数据类型一样。
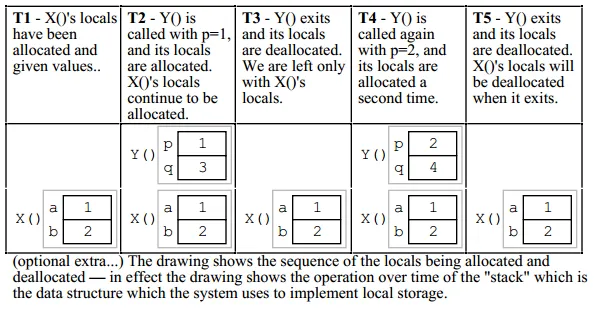
但如果是这样的话,那么在X行之后会发生什么呢?因为显然,我们需要下一步处理a和b,但这将意味着操作系统/CPU(?)必须先弹出d和c才能回到a和b。但接下来它需要c和d,这将是自己给自己找麻烦。
所以,我想知道背后到底发生了什么?
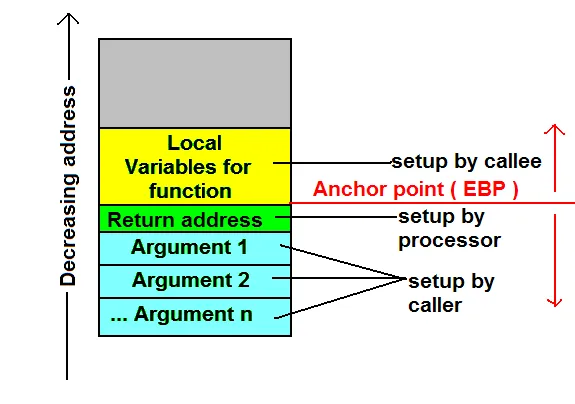
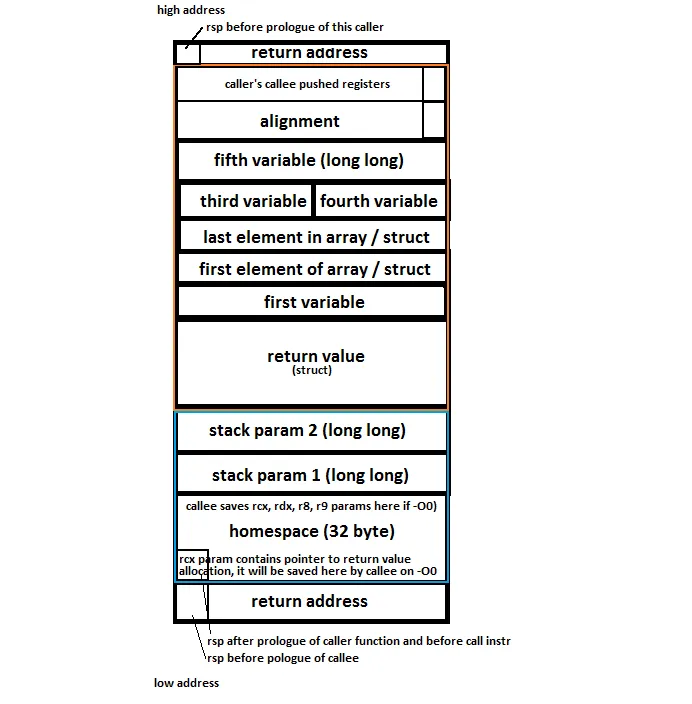
另外一个相关的问题。假设我们像这样向另一个函数传递引用:
fn foo() {
let a = 1;
let b = 2;
let c = 3;
let d = 4;
// line X
doSomething(&a, &b);
doAnotherThing(c, d);
}
根据我的理解,这意味着doSomething中的参数基本上指向与foo中的a和b相同的内存地址。但另一方面,这意味着没有弹出堆栈,直到我们到达a和b的情况。
这两种情况让我觉得我还没有完全掌握堆栈的工作原理以及它如何严格遵循LIFO规则。

{kind=link}
LIFO意味着只能在栈的末尾添加或删除元素,但你始终可以读取/更改任何元素。 - HolyBlackCat