我正在使用Librosa库进行音高和起始点检测。具体而言,我正在使用onset_detect和piptrack函数。
这是我的代码:
def detect_pitch(y, sr, onset_offset=5, fmin=75, fmax=1400):
y = highpass_filter(y, sr)
onset_frames = librosa.onset.onset_detect(y=y, sr=sr)
pitches, magnitudes = librosa.piptrack(y=y, sr=sr, fmin=fmin, fmax=fmax)
notes = []
for i in range(0, len(onset_frames)):
onset = onset_frames[i] + onset_offset
index = magnitudes[:, onset].argmax()
pitch = pitches[index, onset]
if (pitch != 0):
notes.append(librosa.hz_to_note(pitch))
return notes
def highpass_filter(y, sr):
filter_stop_freq = 70 # Hz
filter_pass_freq = 100 # Hz
filter_order = 1001
# High-pass filter
nyquist_rate = sr / 2.
desired = (0, 0, 1, 1)
bands = (0, filter_stop_freq, filter_pass_freq, nyquist_rate)
filter_coefs = signal.firls(filter_order, bands, desired, nyq=nyquist_rate)
# Apply high-pass filter
filtered_audio = signal.filtfilt(filter_coefs, [1], y)
return filtered_audio
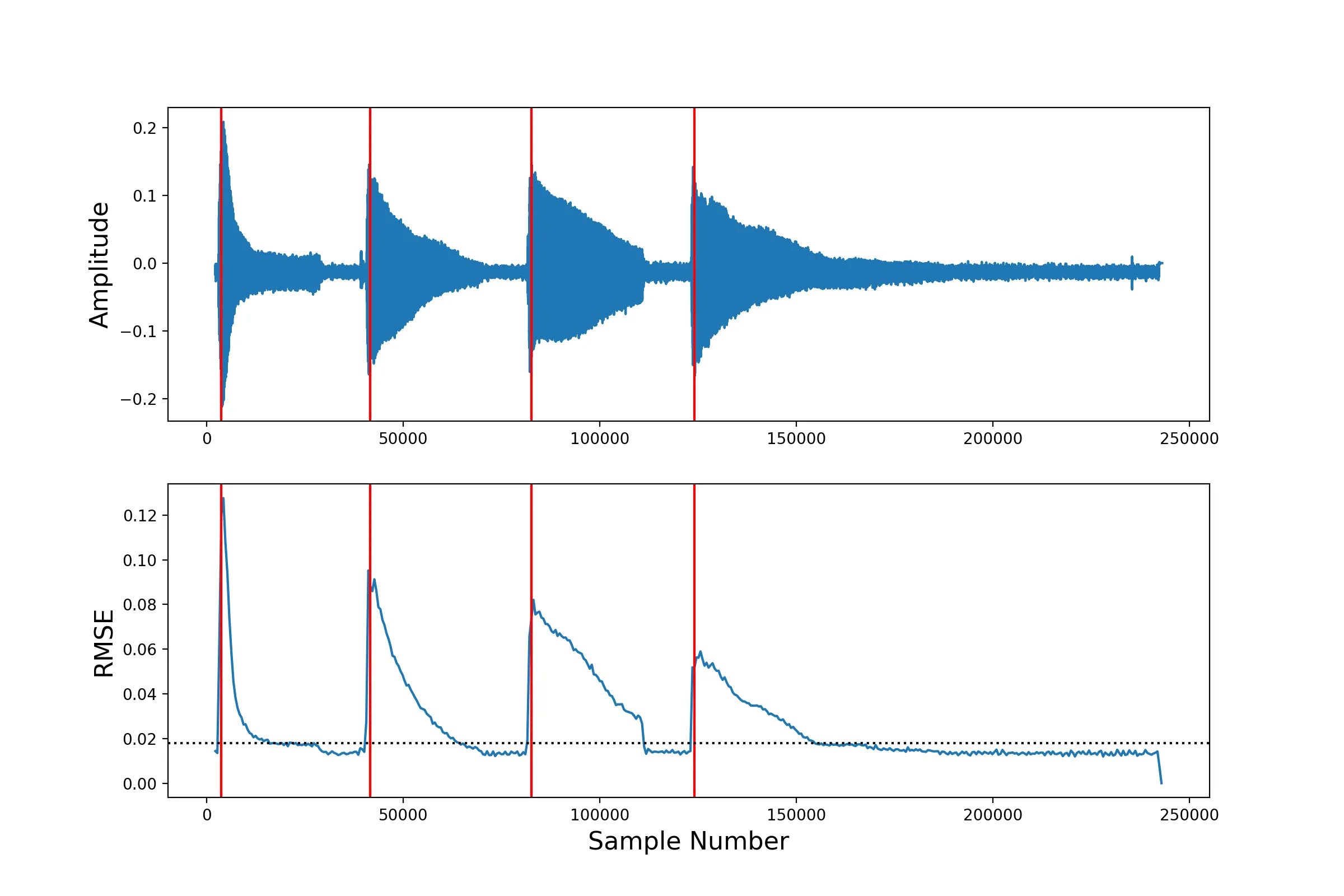
然而,当我尝试使用廉价麦克风录制自己的吉他声音时,就会出现一个很大的问题。我得到了带有噪声的音频文件,例如这个。“onset_detect”算法变得混乱,并认为噪声包含起始时间。因此,我的结果非常糟糕。即使我的音频文件只包含一个音符,也会得到许多起始时间。
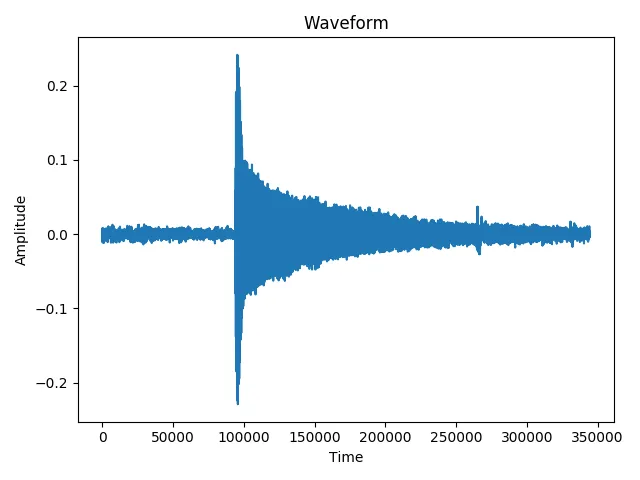
这里有两个波形图。第一个是在录音室中记录的B3音符的吉他样本,而第二个是我对E2音符的录音。
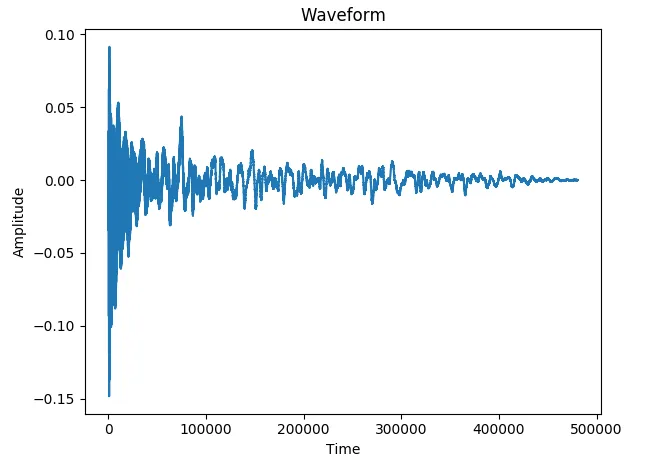
 第一个的结果是正确的B3(检测到了一个起始时间)。
第二个的结果是一个包含7个元素的数组,这意味着检测到了7个起始时间,而不是1个!其中一个元素是正确的起始时间,其他元素只是噪声部分中的随机峰值。
第一个的结果是正确的B3(检测到了一个起始时间)。
第二个的结果是一个包含7个元素的数组,这意味着检测到了7个起始时间,而不是1个!其中一个元素是正确的起始时间,其他元素只是噪声部分中的随机峰值。另一个例子是这个包含B3、C4、D4、E4音符的音频文件:
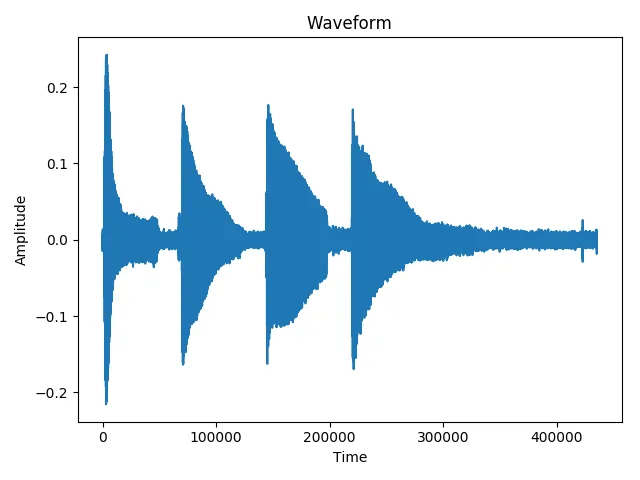 正如你所看到的,噪声很明显,我的高通滤波器也没有起到作用(这是应用滤波器后的波形图)。
正如你所看到的,噪声很明显,我的高通滤波器也没有起到作用(这是应用滤波器后的波形图)。我认为这是噪声的问题,因为那些文件之间的区别就在于此。如果是这样,我该怎么做才能减少噪声?我尝试使用了高通滤波器,但没有改变。